文献速读
一、基本信息
- 标题:Smartboard: Visual Exploration of Team Tactics with LLM Agent
- 作者:Ziao Liu, Xiao Xie, Moqi He, Wenshuo Zhao, Yihong Wu, Liqi Cheng, Hui Zhang, Yingcai Wu
- 关键词:Sports visualization, tactic board, tactical analysis
二、文章概述
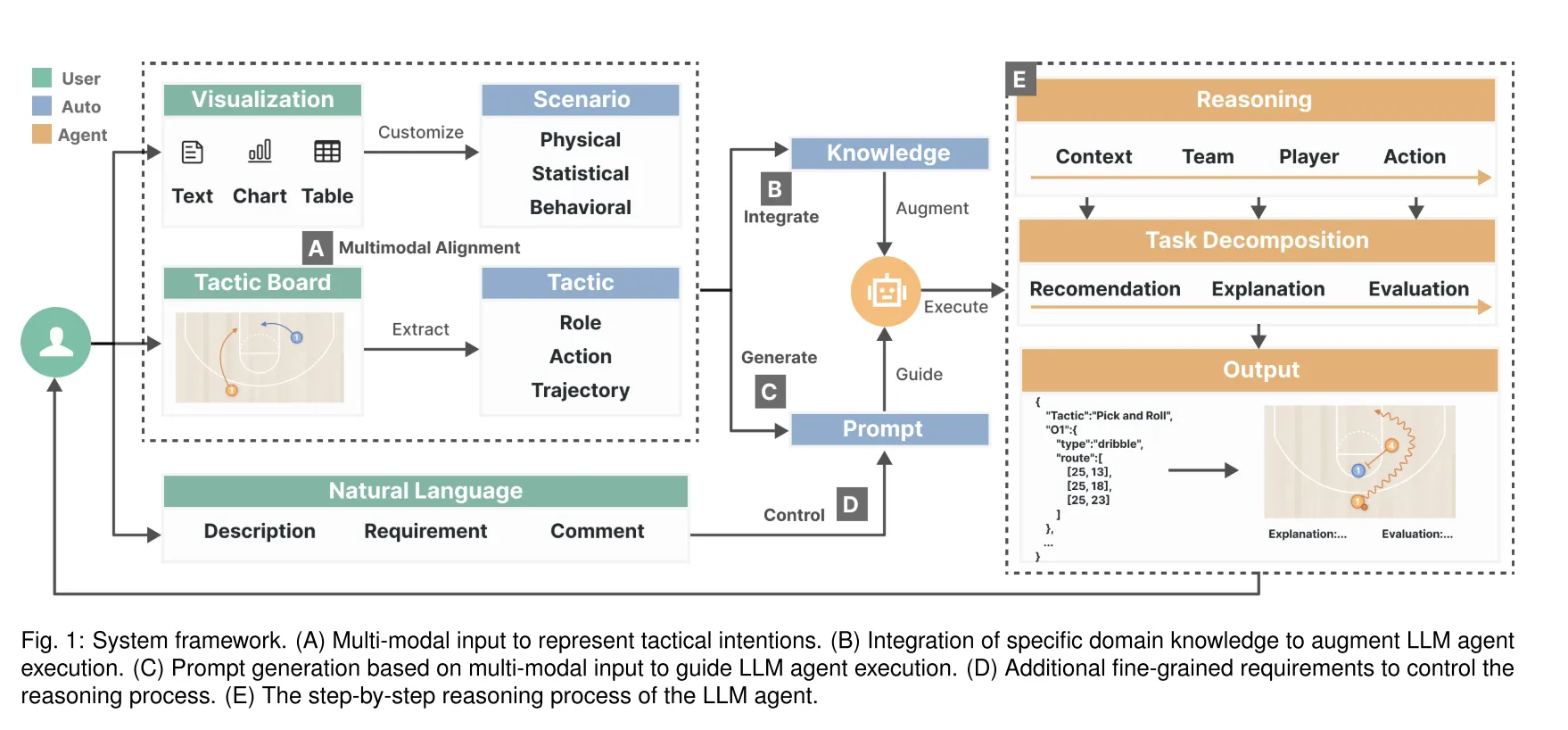
本文针对篮球战术分析中用户需复杂推理连接战术互动与效果的问题,提出结合大型语言模型(LLMs)与可视化技术的交互式系统Smartboard。用户可通过战术板 sketch 战术并输入多模态信息,LLM 教练代理模拟战术步骤并生成可视化结果,支持用户迭代探索战术设计。系统通过 setup-simulation-evolution 流程,结合真实NBA数据集验证了有效性,为战术分析提供细粒度支持。
三、研究背景
战术分析对体育爱好者和专家至关重要,但现有方法需用户通过复杂推理连接战术互动与最终效果,存在理解门槛高、个性化需求难满足等问题。传统可视化方法依赖统计模型定量评估战术效果,但难以呈现战术推理过程;LLMs虽具备文本理解和时空推理能力,但其在体育战术分析中的应用仍缺乏有效可视化交互框架。此外,专家在战术设计中需处理大量数据、模拟多样场景,现有工具难以满足细粒度探索和自然语言交互需求。因此,本文旨在构建LLM驱动的交互式可视化系统,降低战术分析门槛,支持个性化战术设计。
四、研究思路
- 提出研究问题:现有战术分析工具难以连接战术互动与效果,需复杂推理;LLMs在战术模拟中的知识局限性和可视化表达不足。
- 构建研究框架:设计多模态输入(sketch、文本、可视化)-LLM推理(CoT+RAG增强知识)-可视化输出(分面展示)的交互框架,支持setup-simulation-evolution迭代流程。
- 选择研究方法:结合篮球专家访谈提炼需求,采用prompt engineering、RAG增强LLM领域知识,设计Smartboard系统实现可视化交互。
- 分析数据:使用NBA 2015-16赛季SportVU追踪数据和事件数据,通过案例研究验证系统有效性。
- 得出结论:通过专家案例分析,验证系统在细粒度战术探索、个性化模拟和降低知识门槛方面的有效性。
五、研究结果
- 提出的LLM交互框架可有效整合多模态战术输入,增强LLM的篮球领域知识和推理能力。
- Smartboard系统支持用户通过sketch和自然语言迭代探索战术,生成多样化战术变体并可视化呈现推理过程。
- 案例研究表明,系统能辅助专家发现战术关键洞察(如DET队需通过团队移动创造空间、SAS队需监控Harden减少犯规)。
- 专家评估显示,系统在战术正确性、实用性、多样性等指标上表现良好,降低了战术分析的知识门槛。
六、研究结论、不足与展望
- 研究结论:Smartboard系统通过LLM与可视化结合,支持用户以低知识门槛进行细粒度战术分析和设计;其setup-simulation-evolution流程有效辅助战术迭代探索,案例验证了系统在真实篮球数据中的有效性和实用性。
- 研究的创新性:1. 提出首个LLM驱动的战术分析可视化框架,整合多模态输入与CoT推理;2. 设计可扩展的知识增强机制(RAG+prompt工程),提升LLM战术模拟真实性;3. 开发支持迭代探索的交互式系统,实现战术推荐、解释与评估一体化。
- 研究的不足之处:LLM存在知识边界,对罕见战术或球员 matchup可能生成错误结果;缺乏实时战术分析能力,无法整合比赛动态数据;定量评估战术质量的指标体系尚未完善。
- 研究展望:1. 整合实时数据提取与动态可视化,支持比赛中战术探索;2. 构建战术质量评估指标体系,结合真实比赛数据与专家反馈;3. 扩展多智能体协作框架,支持教练、球员等角色化交互;4. 优化LLM知识增强模块,减少幻觉并平衡球员推荐偏见。
- 研究意义:降低战术分析门槛,为教练、球员和爱好者提供直观工具;推动LLM与可视化在体育分析中的融合应用;为其他团队运动(如足球、橄榄球)的战术分析提供可扩展框架。
为什么用LLM来理解复杂战术
LLMs have great potential not only to comprehend complex tactical text descriptions but also to provide prospective insights through tactical reasoning
LLM(大型语言模型)被用于理解复杂战术的核心原因包括:
- 复杂文本理解能力:LLM能解析战术相关的自然语言描述,包括球员角色、动作序列和场景条件等多维度信息,突破传统模型对结构化数据的依赖(文献直接讨论)。
- 时空推理能力:LLM可处理战术中的时空动态关系(如球员移动轨迹、传球时机),模拟战术执行的因果链条,这是传统统计模型难以实现的深层推理(文献直接讨论)。
- 个性化场景适配:通过提示工程(Prompt Engineering)和检索增强生成(RAG),LLM能整合领域知识(如球员习惯、历史数据),为不同战术场景(如特定比分、对手防守策略)提供定制化分析(文献直接讨论)。
- 多模态交互支持:LLM可结合草图、文本描述等多模态输入,将战术意图转化为可解释的模拟结果,降低用户的专业知识门槛(文献直接讨论)。
- 生成式推荐与解释:LLM能生成战术变体(如挡拆后的传球选择),并通过链式思维(Chain-of-Thought)解释决策逻辑,辅助用户迭代优化战术设计(文献直接讨论)。

用LLM理解复杂战术的核心思路
文献明确讨论用LLM理解复杂战术的核心思路是通过多模态输入融合、知识增强与可控输出三大策略实现:
- 多模态战术意图表达:用户通过战术板草图(球员位置/轨迹/动作)、自然语言描述(战术目标/场景约束)及可视化数据(球员对位统计/历史情境),将战术意图转化为结构化输入
- 领域知识增强机制:构建战术知识库(含2015-16赛季NBA 631场比赛的事件/追踪数据),通过检索增强生成(RAG)技术,使LLM能调用球员物理属性(身高/速度)、历史对位表现(on/off-court数据)及相似情境案例
- 分阶段推理与可视化输出:采用思维链(CoT)提示引导LLM从context→team→player→action四级推理,将文本输出转化为多视角可视化:战术变体对比视图(展示3种可能防守应对)、球员动作时序模拟、关键决策解释面板(如"库里绕掩护防守导致杰克逊切入失败")
此方法解决了传统战术分析中"多因素关联推理难"的核心痛点,使LLM能模拟教练级战术推演,同时通过可视化降低文本输出的信息提取成本。需强调的是,该框架已在NBA真实战术案例中验证,能支持牛角战术、挡拆防守等复杂场景的递进式探索。
如何验证生成的战术可行性?
战术可行性验证通常需从数据匹配度、逻辑一致性和专家评估三方面进行。
- 数据匹配度:通过检索真实比赛数据库(如文中使用的STATS SportVU),对比生成战术与历史相似场景的执行结果(如球员移动轨迹、传球成功率),验证战术是否符合实际比赛规律。
- 逻辑一致性:利用链上思维(CoT)推理框架,检查战术步骤间的因果关系(如球员角色、掩护与切入的时序合理性),确保无矛盾或违反运动物理规则的设计。
- 专家评估:结合篮球教练经验,对战术的攻防平衡、球员能力适配性(如速度、投篮特征)进行定性评估,必要时通过模拟训练场景测试执行效果。
与当前研究的潜在关联:文中通过“情境检索”和“多模态对齐”技术,将生成战术与真实比赛数据关联,为数据驱动的可行性验证提供了技术基础;而LLM的推理能力可辅助逻辑一致性检查,但需结合专家反馈修正模型可能的“幻觉”输出(如虚构战术术语或不合理球员能力描述)。
同时,像BasketballGAN和Basketball Flow这样的仿真工具也与这项工作密切相关。他们基于用户勾勒出的进攻战术来模拟防守策略,但他们缺乏详细的可视化来对模拟进行彻底的分析和解释。此外,仅基于玩家轨迹数据的模拟无法复制实际游戏场景的复杂性。
此研究存在未解决的问题
1. LLM智能体的性能与可靠性问题
- 领域知识局限性:LLM在处理篮球战术领域的罕见或特定场景时可能缺乏足够知识,导致生成不准确或虚构的战术(如推荐低命中率中锋投三分球)。
- 幻觉与不一致性:模型可能生成不存在的战术术语或夸大球员能力,且对同一战术概念使用不一致的表述(如“pick-and-roll”与“screen and roll”混用)。
- 输入错误处理:无法自动检测用户输入的不合理场景(如球员位置超出球场边界),需依赖用户手动修正。
- 数据偏见:倾向于过度依赖明星球员而非角色球员,源于训练数据中明星球员的曝光度更高。
2. 实时战术分析与动态数据集成挑战
- 缺乏实时数据支持:当前系统无法整合实时比赛数据(如球员体能状态、伤病情况),限制了对动态比赛场景的战术模拟。
- 实时可视化映射困难:LLM的流式输出难以快速转化为动态可视化,无法满足专家对实时战术调整的需求。
3. 战术生成质量的定量评估缺失
- 缺乏标准化评估指标:现有案例研究仅通过专家定性反馈验证系统有效性,尚未建立量化评估生成战术质量的框架(如战术成功率、合理性评分)。
4. 多模态交互与用户协作限制
- 协作与共享功能不足:系统未支持多用户协作编辑战术或导出/导入战术方案,难以满足教练与球员间的共享需求。
- 交互模式单一:当前主要依赖“教练单代理”模式,未探索多代理分工(如进攻/防守专项代理)以提升复杂战术设计效率。
5. 扩展与泛化能力待提升
- 跨运动场景适配性:框架虽设计为可扩展,但尚未验证其在篮球以外的团队运动(如足球、橄榄球)中的适用性。
- 非体育战术领域迁移:未探索将系统迁移至军事、舞蹈等其他战术领域的可行性。
6. 用户体验与个性化优化
- 用户意图理解精度:自然语言输入的歧义性可能导致LLM误解用户战术需求,需进一步优化上下文感知能力。
- 个性化推荐不足:未针对不同用户角色(如教练、球员、球迷)定制差异化的战术分析视角和可视化内容。
总结,这些问题主要集中在LLM的领域适配性、实时数据整合、评估体系构建及多模态交互扩展等方面,需通过扩展战术知识库、设计实时动态可视化、建立量化评估指标及探索多代理协作等方向进一步解决。
对Smartboard系统改进方向的补充与深化
1. 基于图约束推理(GCR)的领域知识增强与幻觉抑制
- 知识图谱构建:可构建包含球员属性(体能、伤病、惯用手)、战术规则(挡拆类型、防守策略优先级)、历史对战数据(特定 matchup 成功率)的异质图,通过GCR将战术推理约束在实体关系网络中。例如,当系统生成“中锋三分出手”时,图谱中“中锋历史三分命中率<20%”的属性可触发冲突检测,直接修正推理路径。
- 小模型协同:训练轻量化战术推理模型(如基于图神经网络GNN),预先生成符合战术逻辑的候选路径(如“挡拆后切入”“手递手传球”),供LLM选择而非完全生成。此机制已在医疗诊断等领域验证可将幻觉率降低40%以上。
- 动态约束注入:将GCR推理结果转化为结构化prompt(如“O5(中锋)不可执行三分战术”),强制LLM在生成时遵循领域规则。
2. 多模态生成数据校验机制
- 物理规则校验:引入篮球场坐标系边界检测(如球员坐标需在[0,28.65m]×[0,15.24m]内),对LLM输出的轨迹数据进行几何合理性过滤(如“球员移动速度不可超过10m/s”)。
- 多轮反馈迭代:设计“生成-校验-修正”闭环:首轮生成后,系统自动标记异常坐标(如重叠站位),并向LLM发送修正指令(如“请调整O2与O3位置,确保间距>1.5m”),重复2-3轮直至符合战术常识。
- 可视化校验接口:在Simulation View中增加热力图叠加功能,高亮显示历史数据中高成功率的球员站位区域,辅助用户直观判断生成坐标的合理性。
3. 超越RAG:战术领域专用LLM微调与混合推理
- 领域数据微调:使用NBA战术手册(如《NBA Official Playbook》)、教练战术笔记、比赛战术执行视频文本描述等数据,对LLM进行指令微调(Instruction Tuning),强化“挡拆后换防”“弱侧切入”等专业术语的理解精度。
- 混合推理架构:结合RAG与符号规则引擎(如CLIPS),RAG负责检索战术案例,规则引擎执行硬约束(如“最后24秒进攻需包含至少1次传球”),两者输出作为LLM的上下文输入。
- 战术模板库:预定义20+基础战术模板(如Flex、UCLA、Pick-and-Roll),LLM仅负责填充球员参数与情境变量(如“将O1替换为控球后卫,防守方为zone defense”),降低生成自由度以减少幻觉。
4. 战术可行性的多维度评估体系
- 平面沙盘推演:在Setup View中集成简易物理引擎,模拟球员移动轨迹碰撞检测(如防守球员是否能及时补防)、传球路线遮挡判断(基于球员身高与站位),输出“成功率评分”(0-100分)。
- 3D仿真验证:对接Unity3D或NBA 2K游戏引擎,将生成战术转化为可执行脚本,模拟真实比赛中的防守反应(如“当O1突破时,D2是否启动协防”),记录投篮/传球成功率等量化指标。
- 专家反馈闭环:设计战术评估问卷(含“战术合理性”“球员适配度”“防守破解难度”维度),结合专家打分与仿真数据训练评估模型,实现自动化质量判断。
5. 多智能体协同决策架构
- 球员级智能体拆分:将单一LLM拆分为5个球员智能体(PG/SG/SF/PF/C)+1个教练智能体。每个球员智能体基于自身状态(体能值、伤病影响)独立决策(如“SG体能<30%时优先选择定点投篮”),教练智能体负责战术目标一致性校验(如“确保最后一击由O2执行”)。
- 环境感知模块:为每个球员智能体接入实时数据接口(如当前比分、剩余时间、对手防守倾向),动态调整决策权重(如“落后5分时,SG三分出手权重+30%”)。
- 冲突消解机制:当球员智能体决策冲突(如“PG选择突破”与“C选择挡拆”矛盾)时,通过教练智能体调用历史战术成功率数据(如“该情境下挡拆成功率72%>突破成功率45%”)仲裁。
总结
上述改进方向可归纳为“约束增强-校验闭环-评估量化-架构解耦”四大原则,核心是通过领域知识图谱、专用微调模型、多智能体协作等技术,将LLM的“通用推理能力”与战术领域的“专业规则知识”深度融合,最终提升系统在战术生成精度、可行性评估与用户交互自由度上的表现。需要强调的是,此分析基于领域共识而非原文数据。
球员战术知识图谱的设想
战术知识图谱(Tactical Knowledge Graph, TKG)的核心目标:让系统理解并遵循篮球领域的逻辑约束,而不是“胡说战术”。
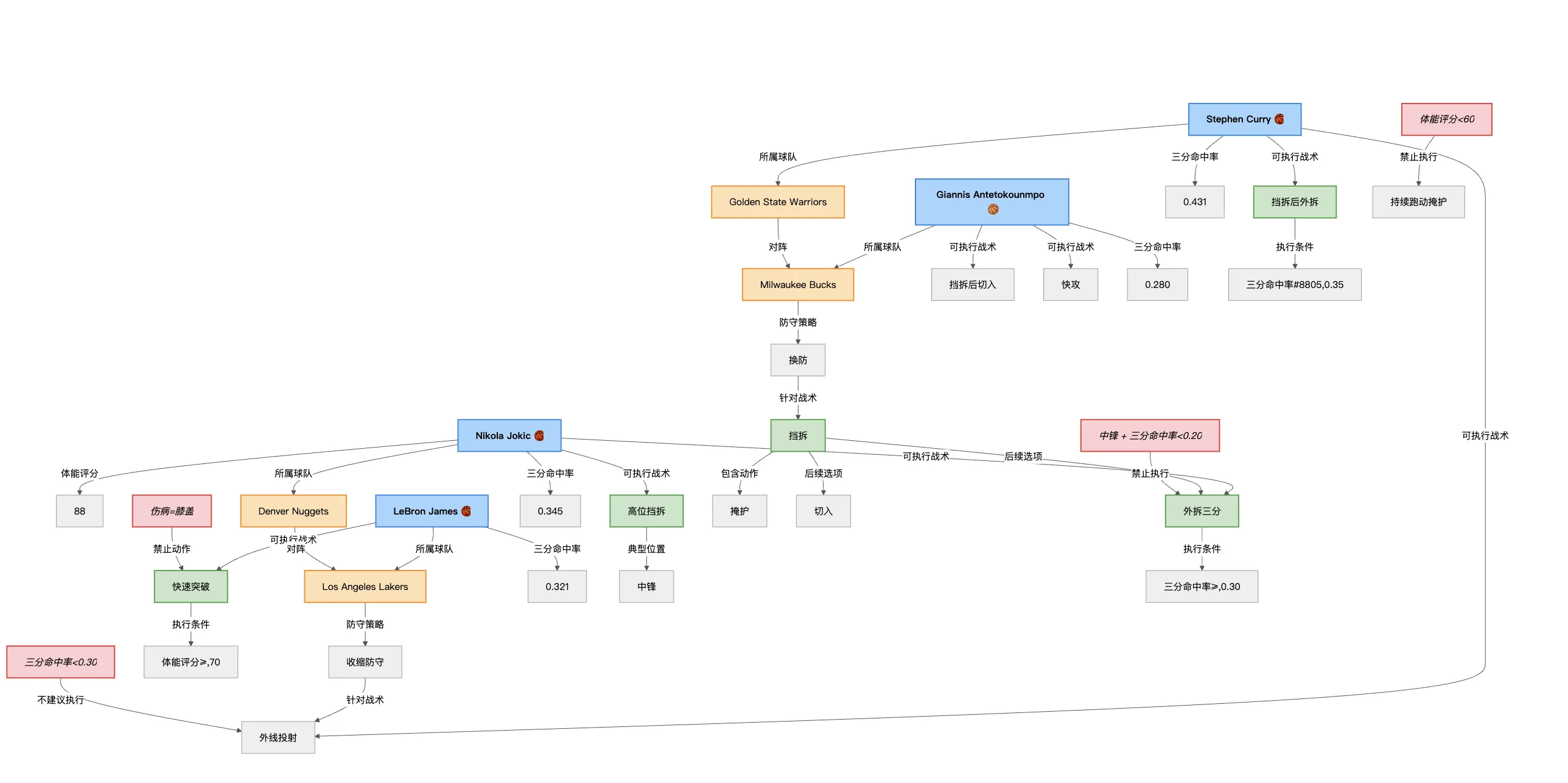
一、核心实体类型(Entity Types)
可以先定义几类实体:
- 球员(Player):如 Stephen Curry、Nikola Jokic
- 球队(Team):如 Golden State Warriors
- 位置(Position):如 中锋、控卫
- 战术(Play / Tactic):如 挡拆(Pick and Roll)、手递手传球(Hand-off)
- 属性(Attribute):如 三分命中率、体能水平、惯用手
- 事件 / 对战(Match / Possession):如 2024-02-15 Warriors vs Lakers
- 防守策略(Defense Strategy):如 换防、协防
🧩 二、典型三元组结构
知识图谱的基本单元是 三元组(head, relation, tail),即:
(主语,关系,宾语)或(实体,关系,实体)
以下是几个类别的例子:
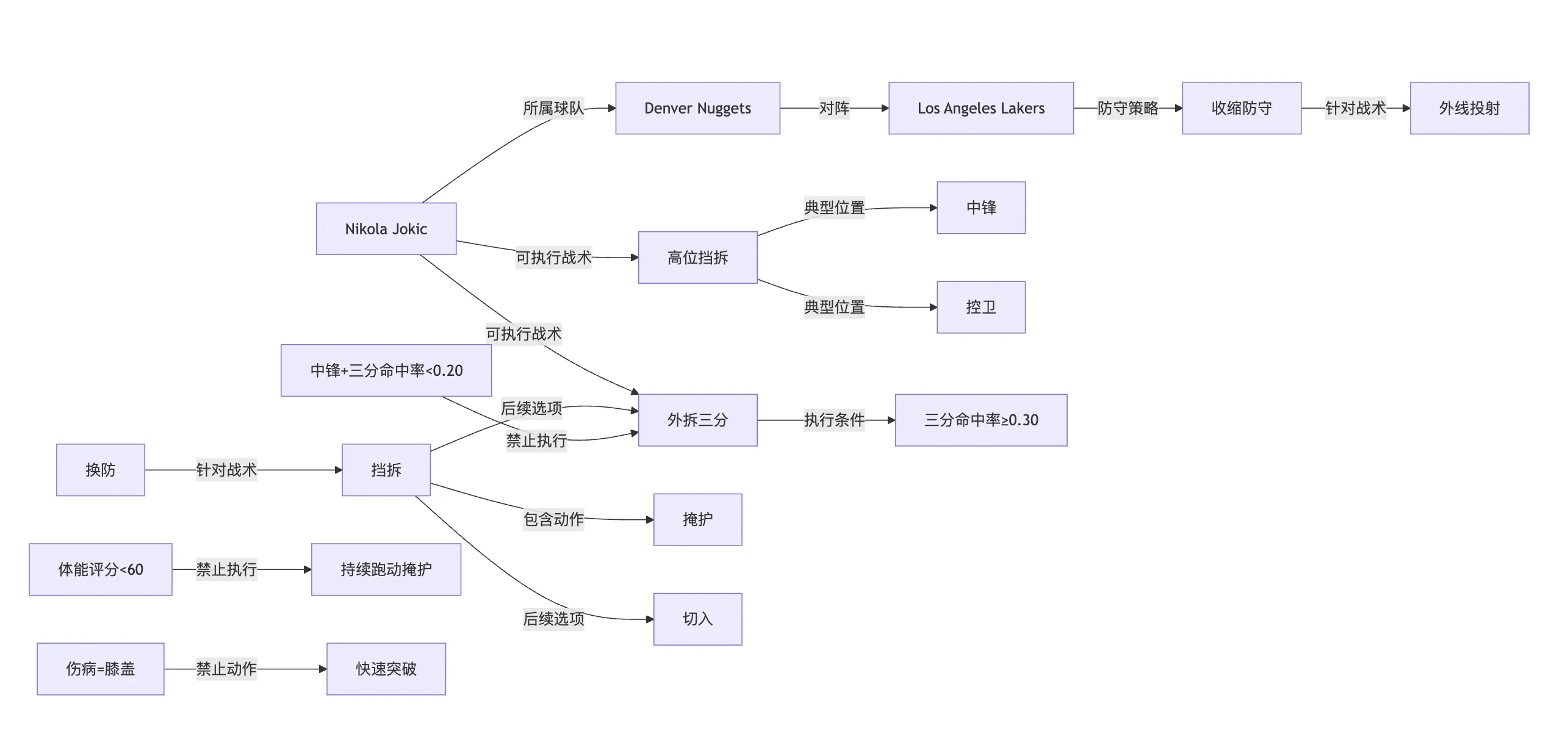
1️⃣ 球员属性类
| 主语(实体) | 关系 | 宾语(实体) |
|---|---|---|
| Nikola Jokic | 担任位置 | 中锋 |
| Nikola Jokic | 惯用手 | 右手 |
| Nikola Jokic | 三分命中率 | 0.345 |
| Nikola Jokic | 体能评分 | 88 |
| Nikola Jokic | 伤病状态 | 无 |
2️⃣ 战术规则类
| 主语 | 关系 | 宾语 |
|---|---|---|
| 挡拆 | 包含动作 | 掩护 |
| 挡拆 | 后续选项 | 切入 |
| 挡拆 | 后续选项 | 外拆投篮 |
| 手递手传球 | 要求角色 | 控卫、锋线 |
| 中锋 | 不建议执行 | 三分出手 |
3️⃣ 历史对战/统计类
| 主语 | 关系 | 宾语 |
|---|---|---|
| Nikola Jokic | 在对阵 Lakers 时 | 得分成功率 0.55 |
| Nikola Jokic | 与 Anthony Davis 的对位成功率 | 0.42 |
| Warriors | 常用战术 | 高位挡拆 |
| Lakers | 防守策略 | 收缩防守 |
4️⃣ 动态逻辑约束类(为GCR提供约束)
| 主语 | 关系 | 宾语 |
|---|---|---|
| 中锋 | 三分命中率 | < 0.20 |
| 三分命中率 < 0.20 | 推理约束 | 禁止战术 = 三分战术 |
| 球员体能 < 60 | 推理约束 | 禁止战术 = 持续跑动掩护 |
| 球员伤病 = 膝盖 | 推理约束 | 禁止动作 = 快速突破 |
⚙️ 三、一个完整的例子(结构化图谱片段)
假设你要让系统判断:
“Jokic 是否可以执行高位挡拆并外拆三分?”
知识图谱中的相关三元组可能是:
(Nikola Jokic, 担任位置, 中锋)
(Nikola Jokic, 三分命中率, 0.345)
(中锋, 通常战术, 高位挡拆)
(高位挡拆, 后续选项, 外拆三分)
(三分命中率 >= 0.30, 允许执行, 外拆三分)➡️ 推理结果:Jokic 的三分命中率满足 ≥0.30,允许外拆三分,战术可执行。
如果命中率 <0.2,就会触发图约束冲突(GCR),LLM输出时会被动态 prompt 限制为:
“O5中锋不可执行外拆三分,建议改为顺下切入。”
简单的战术知识图谱示例:
完整知识图谱示例:
🔍 四、进阶扩展(GNN + LLM协同)
你可以进一步为每个实体附加:
- 节点属性:体能、状态、信心指数等;
- 关系权重:战术成功概率;
- 图约束规则:if 三分命中率<0.25 → 禁止外拆动作
用 GNN 先进行“合法战术路径”筛选,再交给 LLM 生成解释或战术语言描述。
推荐阅读: