文章来源:
arXiv:
https://arxiv.org/abs/2507.06272GitHub:
https://github.com/echo840/LIRA
LIRA: Inferring Segmentation in Large Multi-modal Models with Local Interleaved Region Assistance(ICCV2025)
文献速读
一、基本信息
- 标题:LIRA: Inferring Segmentation in Large Multi-modal Models with Local Interleaved Region Assistance
- 作者:Zhang Li, Biao Yang, Qiang Liu, Shuo Zhang, Zhiyin Ma, Liang Yin, Linger Deng, Yabo Sun, Yuliang Liu, Xiang Bai
- 关键词:Large Multi-modal Models (LMMs), Segmentation, Comprehension, Hallucination Mitigation, Feature Fusion
二、文章概述
本文针对大型多模态模型(LMMs)在分割和理解任务中存在的分割不准确与理解幻觉问题,提出了LIRA框架。该框架通过语义增强特征提取器(SEFE)融合高层语义与细粒度像素特征,提升分割精度;通过交错局部视觉耦合(ILVC)训练范式,建立局部图像区域与文本描述的显式映射,减少幻觉。实验表明,LIRA在分割和理解任务上均达到SOTA性能,且在保持理解能力的同时实现高效分割。
三、研究背景
现有LMMs虽已扩展至像素级分割任务,但存在两大局限:一是视觉理解能力弱导致分割不准确,如无法有效嵌入位置信息至<seg> token;二是缺乏细粒度感知,难以建立局部图像特征与文本描述的明确关联,易产生幻觉。此外,分割与理解任务的协同训练常导致理解性能下降(如OMG-LLaVA性能下降14.3%)。因此,需探索一种既能提升分割精度,又能减少幻觉且不损害理解能力的方法,以充分发挥视觉理解与分割的互补性。
四、研究思路
- 提出研究问题:分析现有LMMs分割误差与幻觉成因,聚焦如何通过特征融合与局部耦合提升分割精度并减少幻觉。
- 构建研究框架:设计LIRA框架,包含SEFE(融合语义与像素特征)和ILVC(建立
<mask, region, text>三元组对齐)。 - 选择研究方法:采用两阶段训练,第一阶段对齐像素编码器与LLM,第二阶段通过LoRA微调LLM,结合文本生成损失与分割损失端到端优化。
- 分析数据:在RefCOCO、GranDf等数据集上评估分割性能,在MME、POPE等数据集评估理解能力,并通过AttrEval量化语义推理能力。
- 得出结论:验证SEFE和ILVC的有效性,证明LIRA在分割与理解任务上的协同提升。
五、研究结果
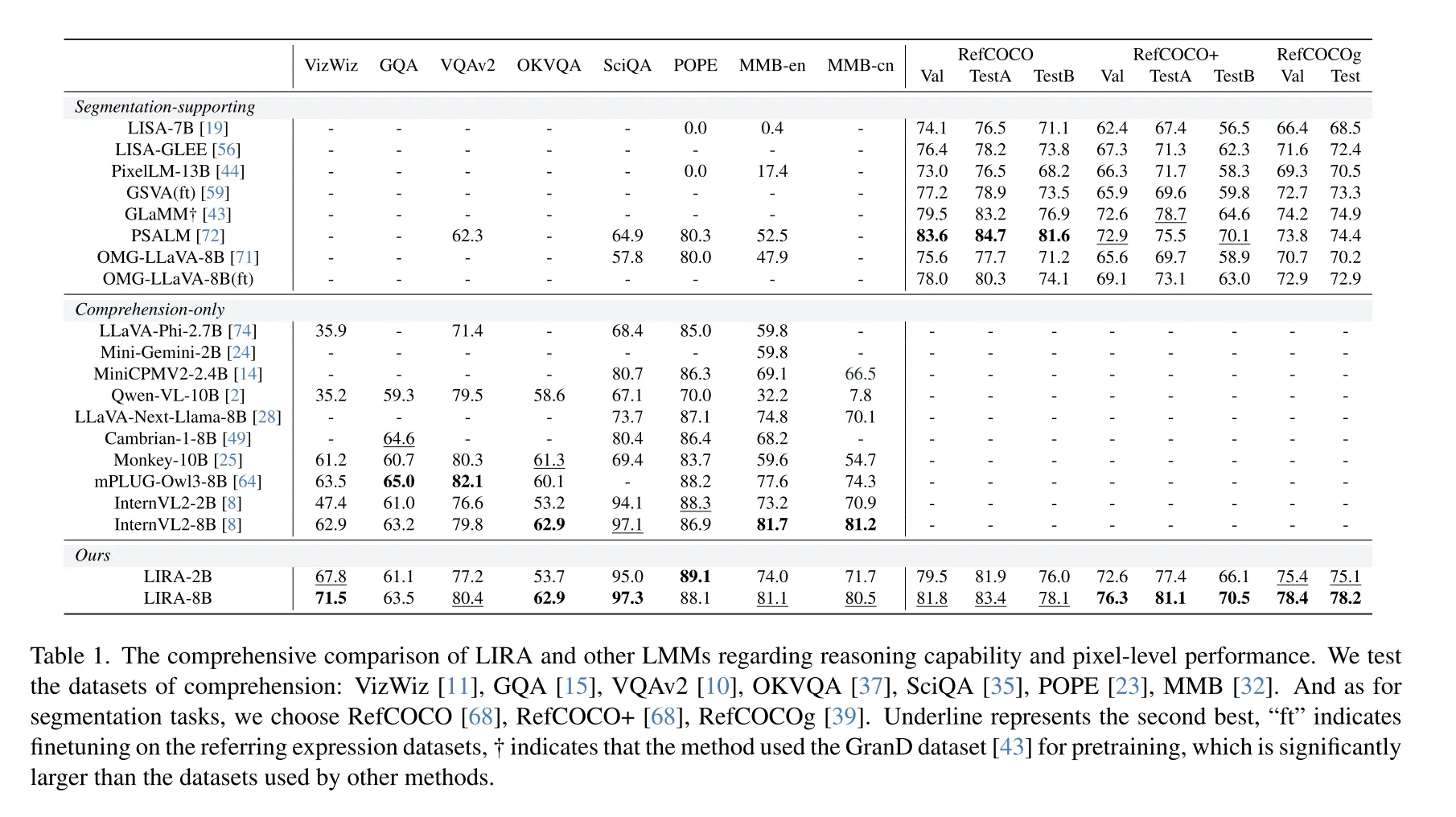
- LIRA在分割任务上平均性能超现有模型,如RefCOCOg测试集达78.2%,5项分割指标中获4项SOTA。
- 理解任务上,LIRA-8B在8个数据集平均准确率78.2%,较OMG-LLaVA(70.2%)显著提升,且协同训练仅导致理解性能下降0.2%(OMG-LLaVA下降14.3%)。
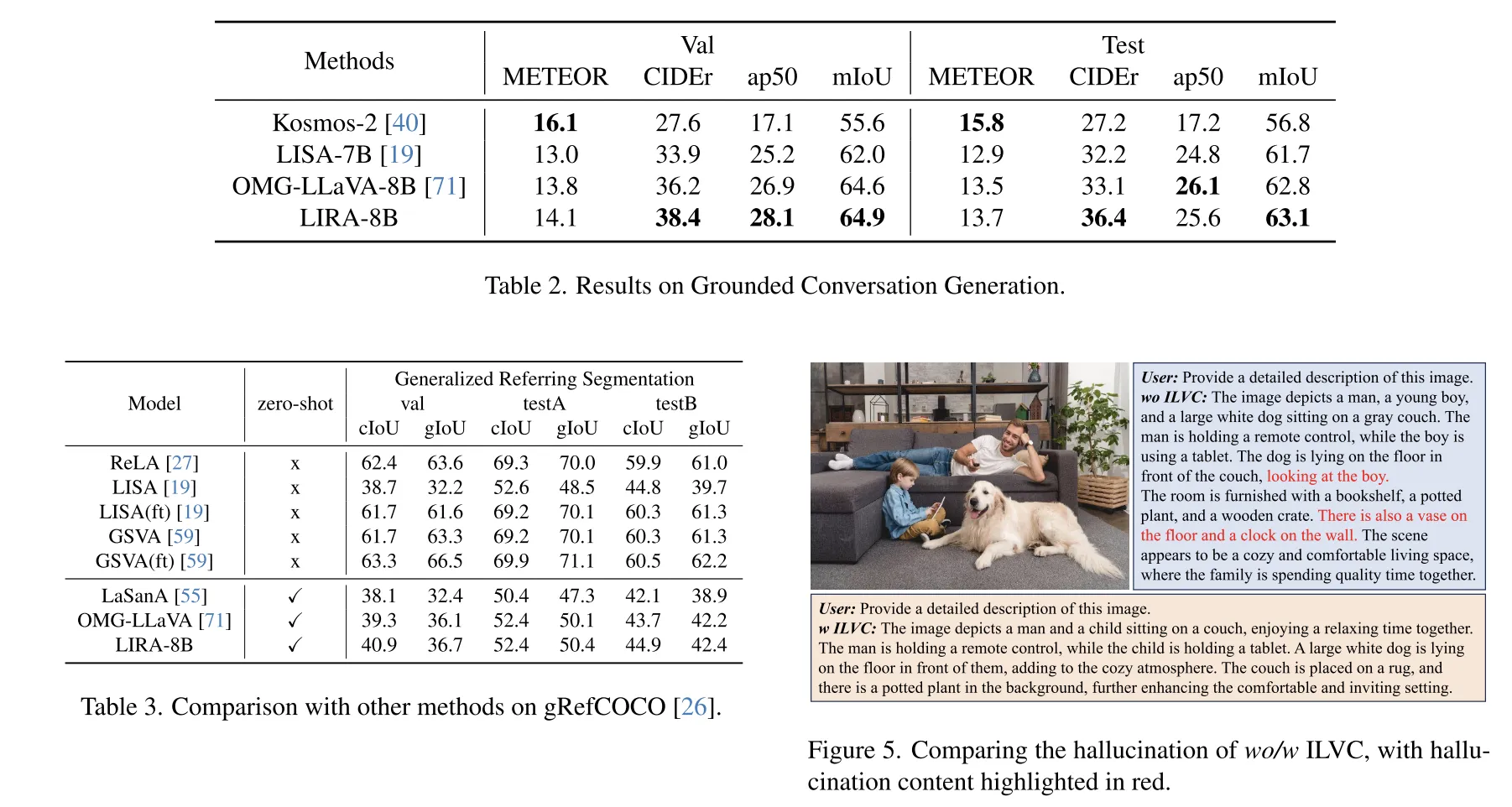
- ILVC有效减少幻觉,ChairS幻觉率降低4.8%,生成描述更准确(如消除“不存在的花瓶”等错误)。
- AttrEval数据集上,LIRA的属性推理Acc1达25.7%,VQA准确率58.6%,验证语义对齐能力。
六、研究结论、不足与展望
- 研究结论:LIRA通过SEFE融合语义与像素特征提升分割精度,通过ILVC建立局部视觉-文本对齐减少幻觉,实现分割与理解任务的协同优化,在多个基准测试中达SOTA性能。
- 研究的创新性:1)SEFE动态融合高层语义与细粒度像素特征,增强视觉理解;2)ILVC引入
<mask, region, text>三元组训练范式,显式耦合局部特征与描述;3)提出AttrEval数据集量化<seg>token语义推理能力。 - 研究的不足之处:1)ILVC在复杂任务(如接地对话生成)中引入约15%推理开销;2)AttrEval中属性推理Acc1仅25.7%,语义理解仍有提升空间;3)多目标分割时可能存在误差累积(需通过双prompt控制缓解)。
- 研究展望:1)探索更高效的局部特征耦合方法以降低推理开销;2)扩展AttrEval至更多属性类别(如材质、动作),提升语义推理能力;3)研究跨模态知识蒸馏,将大模型能力迁移至轻量级模型;4)结合视频数据,实现动态场景的分割与理解协同。
- 研究意义:突破了LMMs分割与理解性能难以兼顾的瓶颈,为多模态模型的细粒度感知与语义对齐提供新范式,推动LMMs在接地对话、机器人视觉等实际场景的应用。
先前的LMMs在分割图像理解存在的问题
先前的研究在大型多模态模型LMMs(large multi-modal models)的分割和理解任务中主要存在以下问题:
1. 分割精度不足
- 核心原因:视觉理解能力薄弱,难以有效嵌入精确的位置、颜色等属性信息到
<seg>标记中。例如,OMG-LLaVA在复杂场景(如“靠近白色汽车的红色巴士”)中无法准确分割目标,其<seg>标记的logits分析显示,模型对“左/右”等位置属性的预测概率与实际分割结果高度相关,但因语义理解不足导致错误。 - 表现:在RefCOCO等数据集上,现有方法对属性依赖型分割(如颜色、相对位置)的准确率较低。
2. 理解任务中的幻觉现象
- 核心原因:局部视觉特征与文本描述缺乏显式对齐,模型依赖位置查询而非直接视觉特征输入,导致生成不存在的物体或属性(如“地板上的花瓶”)。
- 表现:在图像描述任务中,现有模型(如OMG-LLaVA)常生成与图像内容不符的细节,ChairS等幻觉评估数据集上的错误率较高。
3. 分割与理解任务的冲突
- 核心问题:同时训练分割和理解数据时,理解性能显著下降。例如,OMG-LLaVA在5个理解数据集上的准确率从69.9%降至55.6%,而仅训练理解数据时性能保持稳定。
- 本质矛盾:分割任务需要细粒度像素特征,而理解任务依赖高层语义,现有方法未能有效融合两者。
4. 属性推理能力有限
- 问题:模型难以从文本查询中推断隐含属性(如“银色汽车”的颜色、“前方的人”的位置),导致分割和问答任务中的属性判断准确率低。AttrEval数据集显示,现有模型在颜色和位置属性的VQA准确率仅为41.1%。
5. 多目标分割的误差累积
- 挑战:在多物体场景中,初始分割掩码的误差可能传递到后续步骤,影响整体性能。例如,ILVC机制在多轮分割中可能因局部特征提取错误导致连锁错误。
关键关联
这些问题均源于视觉-语义对齐不足:现有模型未能有效融合像素级特征与语义信息,且缺乏细粒度的局部视觉-文本耦合机制。LIRA通过SEFE(语义增强特征提取)和ILVC(交错局部视觉耦合)分别针对性解决分割精度和幻觉问题,并通过协同训练缓解任务冲突。
LIRA如何解决上述问题?
文献明确讨论LIRA解决大型多模态模型(LMMs)中不准确分割和幻觉理解问题的方法。
LIRA通过两个核心组件解决问题:
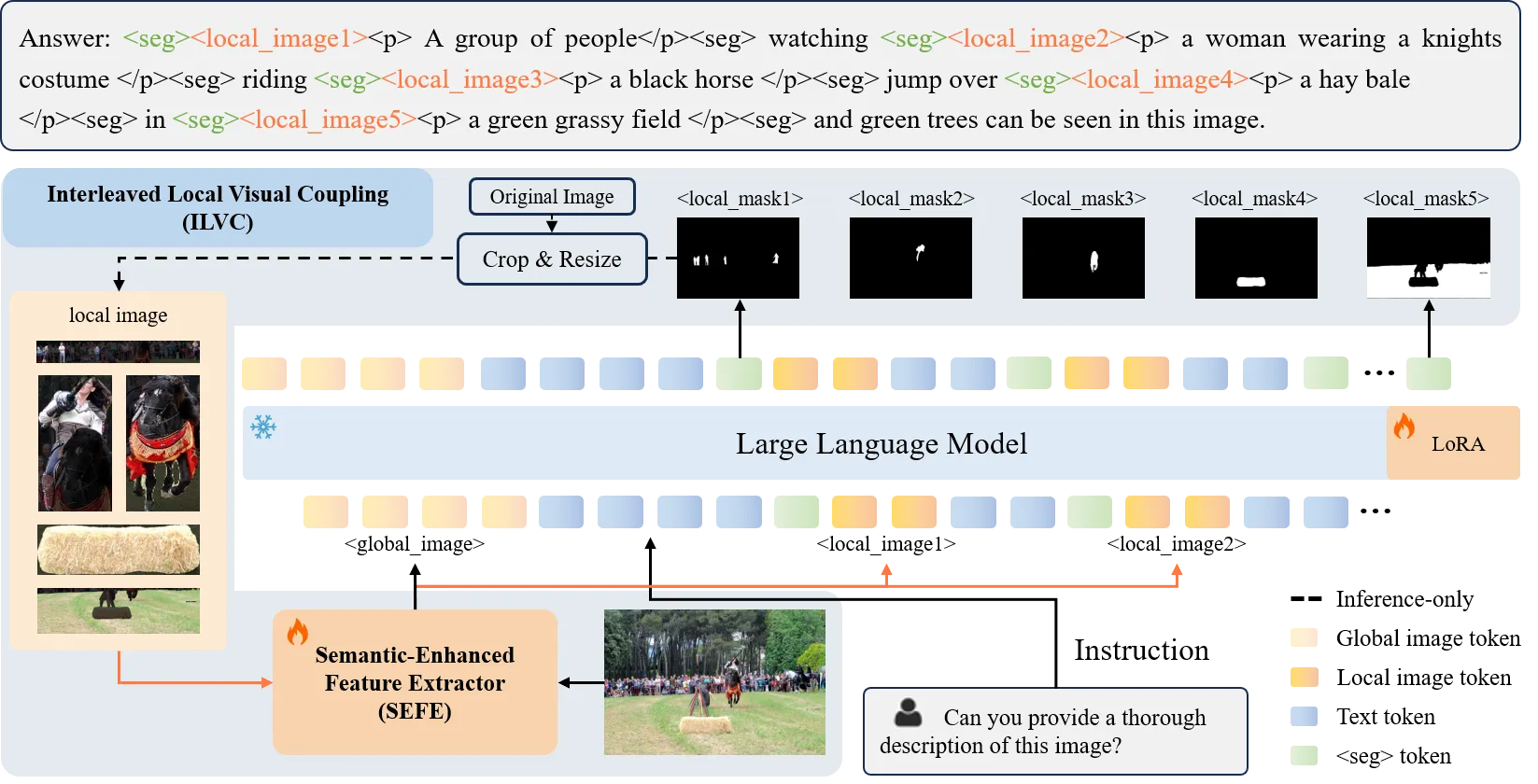
- 语义增强特征提取器(SEFE):融合语义编码器(来自预训练LMM)和像素编码器(来自分割模型)的特征,通过多头交叉注意力层对齐语义与像素级信息,提升对象属性推理能力,从而改善分割准确性。
- 交错局部视觉耦合(ILVC):基于生成的分割掩码提取局部图像区域,将其编码为特征后重新输入LLM,生成区域描述,建立<掩码-区域-文本>三元组对齐,提供细粒度监督以减少幻觉。
此外,LIRA通过联合训练分割与理解数据,缓解了以往方法中分割任务对理解性能的损害,在保持高理解精度(75.2%)的同时,显著提升分割能力。
总结LIRA的核心贡献
LIRA的核心贡献可概括为以下三点:
提出语义增强特征提取器(SEFE)
- 功能:通过融合语义编码器(来自预训练多模态模型)和像素编码器(来自分割模型)的特征,提升对象属性推理能力。
- 实现:将语义特征与像素特征通过多头交叉注意力(MHCA)动态融合,增强视觉理解与像素级推理的衔接,解决传统模型因视觉理解薄弱导致的分割定位偏差问题(如方向、颜色属性编码错误)。
- 效果:在2B和7B模型上,理解任务平均提升5.1%-5.7%,分割任务提升3.4%-3.8%。
提出交错局部视觉耦合(ILVC)训练范式
- 功能:通过<mask, region, text>三元组交互,建立局部图像区域与文本描述的显式对齐,缓解幻觉问题。
- 实现:基于分割掩码提取局部图像区域,将其特征重新输入LLM以生成区域专属描述,形成“全局-局部”特征交替优化。
- 效果:在AttrEval数据集上,属性推理Top-1准确率达25.7%(较OMG-LLaVA提升19.4%),幻觉指标ChairS降低3.0%-4.8%,生成描述中无意义对象(如“不存在的花瓶”)显著减少。
focus on the visual tokens derived from the sub-image, en- abling it to generate more accurate and detailed descriptions of the specified area and thereby minimizing the occurrence of hallucinations.
专注于从子图像衍生的视觉标记,使其能够对指定区域产生更准确和详细的描述,从而最大限度地减少幻觉的发生。
实现分割与理解能力的协同优化
- 核心发现:令牌的潜在语义与分割精度正相关,提出AttrEval数据集量化此关系。
- 优势:在联合训练分割与理解数据时,仅导致理解性能轻微下降(75.2% vs. 75.3%),而OMG-LLaVA下降14.3%;在RefCOCO/+/g等分割数据集上平均性能达78.2%,MME理解任务得分75.2%,实现“双高”性能(见图1)。
数据集与验证
- 构建AttrEval数据集,包含1436个VQA样本和618个引用分割样本,验证模型对颜色、位置等属性的推理能力。
- 在8个理解数据集(如VQAv2、OKVQA)和3个分割数据集上全面验证,LIRA-8B在RefCOCOg测试集达78.2%,超越PSALM、OMG-LLaVA等方法。
核心价值
通过视觉理解与分割的互补关系,突破传统模型“分割-理解”能力冲突的瓶颈,为多模态模型在精细视觉推理(如属性感知分割、接地对话生成)提供新范式。
对比其他LMMs
unlike previous methods that may achieve improvements through task-specific fine-tuning after the instruction tuning stage, we only perform one instruction tuning stage.
以前的方法可能在指令调优阶段之后通过特定任务的微调来实现改进,而我们只执行一个指令调优阶段。
结论
在本文中,作者提出了一种新的范例LIRA,它可以在减少幻觉的同时使基于理解的LMM具有分割能力。实验证明了其方法在多个基准测试中的改进,包括理解、分割、接地对话生成和幻觉。此外,还引入了AttrEval数据集,用于评估模型对对象属性的理解能力。通过分析发现对图像属性的深入理解可以提高模型的性能。在未来,进一步探索文本-视觉关联和属性推理是必要的。
推荐阅读: