文章来源:https://arxiv.org/abs/2509.23392
Github:https://github.com/JinyiHan99/Just-Enough-Think
文献速读
一、基本信息
- 标题:Your Models Have Thought Enough: Training Large Reasoning Models to Stop Overthinking
- 作者:Jinyi Han, Ying Huang, Ying Liao, Zishang Jiang, Xikun Lu, Haiquan Zhao, Xinyi Wang, Guanghao Zhou, Sihang Jiang, Jiaqing Liang, Weikang Zhou, Zeye Sun, Fei Yu, Yanghua Xiao
- 关键词:Large Reasoning Models (LRMs), overthinking, Just-Enough Thinking (JET), reinforcement learning, trajectory truncation, length reward
二、文章概述
本文针对大型推理模型(LRMs)在深度推理时存在的“过度思考”导致计算成本过高的问题,提出了Just-Enough Thinking(JET)方法。JET受证据积累模型启发,通过轨迹截断在强化学习rollout阶段构建分布一致的短推理路径,并设计质量控制的长度奖励,引导模型主动终止冗余推理。实验表明,JET在多个推理任务上显著减少输出长度(如DeepSeek-Distill-Qwen-1.5B在Olympiad基准上减少46.3%长度),同时提升或保持准确率,验证了其高效推理能力。
三、研究背景
大型推理模型(LRMs)在数学问题解决等复杂任务上表现优异,但其类System-2认知的推理过程常伴随冗余步骤,导致计算成本过高,即“过度思考”。现有强化学习方法在训练中难以生成短推理路径,且人工压缩的短路径易与模型自然生成分布脱节,影响学习效果。受认知科学中证据积累模型启发,本文发现LRMs在推理早期已积累足够信息,后续步骤冗余,因此需训练模型主动终止不必要推理,以平衡准确性与效率。
四、研究思路
- 提出研究问题:LRMs存在过度思考问题,现有方法难以高效生成短推理路径,如何训练模型主动终止冗余推理?
- 构建研究框架:基于证据积累模型假设,设计两阶段rollout策略(全轨迹生成+轨迹截断)和质量控制长度奖励,形成JET方法。
- 选择研究方法:采用强化学习框架,结合轨迹截断(Progressive Early-Stopping策略)和混合奖励(正确性+格式+长度奖励)训练模型。
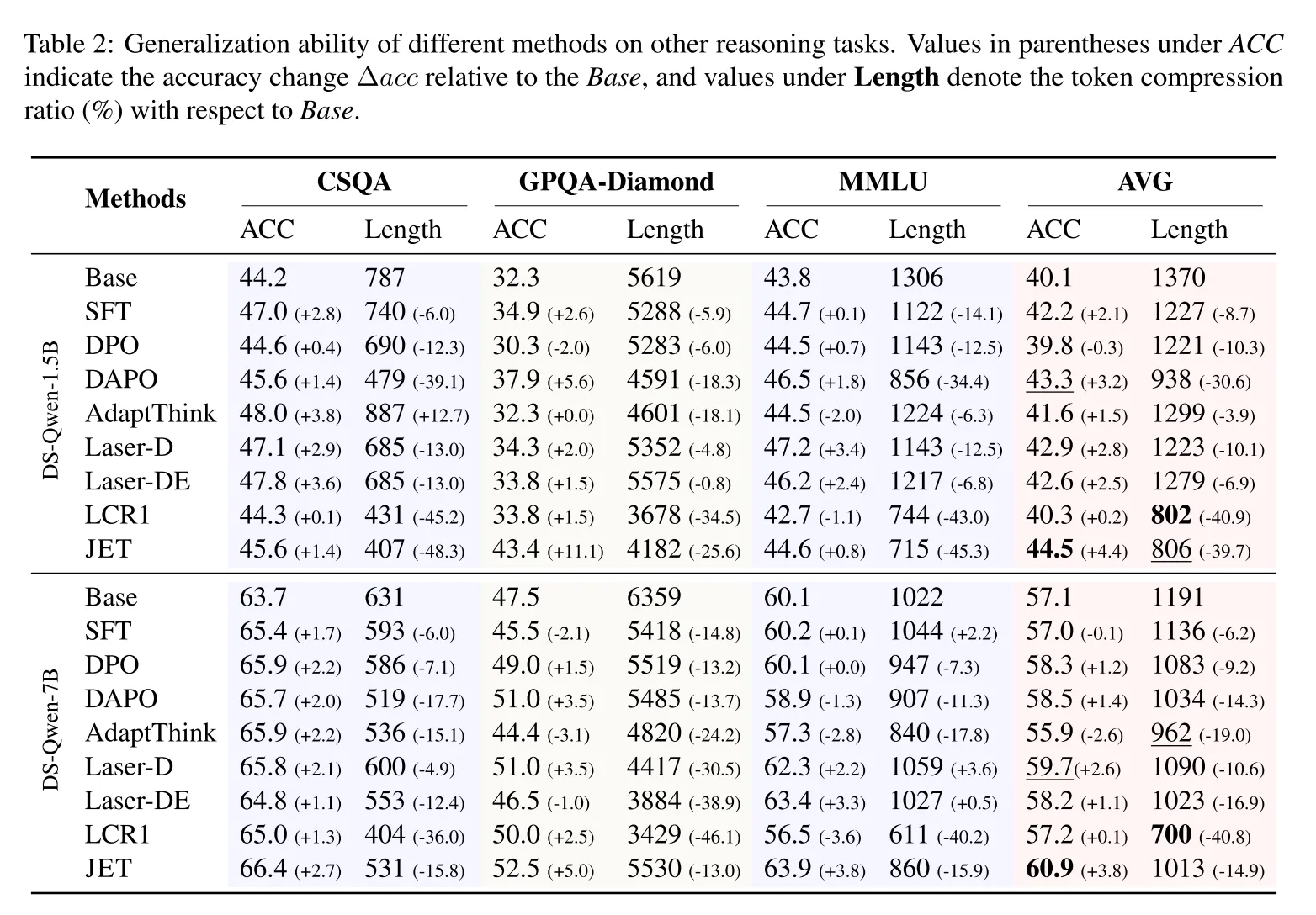
- 分析数据:在数学推理(MATH500、AIME24等)和跨领域推理(CSQA、GPQA等)数据集上,对比JET与SFT、DPO等基线的准确率和长度压缩率。
- 得出结论:JET能有效减少推理长度并保持准确率,且在不同模型规模和任务上具有泛化性。
五、研究结果
- JET显著降低输出长度,DeepSeek-Distill-Qwen-1.5B在Olympiad基准上压缩46.3%长度,同时提升4.6%准确率。
- 在数学推理任务中,JET平均压缩率达39.7%(1.5B模型),且复杂任务(如AIME24)准确率提升2.7%-3.3%。
- 跨领域泛化能力强,在GPQA-Diamond等任务上,1.5B模型准确率提升11.1%,长度压缩25.6%-48.3%。
- 不同模型规模(1.5B/7B)上表现稳定,且推理效率(生成速度)提升最高达5倍。
六、研究结论、不足与展望
- 研究结论:JET通过轨迹截断和质量控制长度奖励,有效训练LRMs主动终止冗余推理,实现高效推理。在保持或提升准确率的同时,显著减少输出长度,且在不同模型规模和任务上具有稳定性和泛化性。
- 研究的创新性:1. 提出轨迹截断策略,从模型自然生成的长轨迹中构建分布一致的短推理路径;2. 设计质量控制长度奖励,优先保证正确性,再鼓励简洁性,平衡准确率与效率。
- 研究的不足之处:1. 截断位置依赖Progressive Early-Stopping策略,可能未完全找到最优截断点;2. 主要在数学推理任务验证,复杂多模态推理场景的适用性需进一步测试;3. 训练过程中需生成多个截断变体,增加计算开销。
- 研究展望:1. 探索动态截断策略,结合任务难度自适应调整推理长度;2. 扩展至多模态推理任务,验证JET在图像-文本等场景的高效性;3. 优化奖励函数设计,如引入不确定性量化以更精准判断信息充分性;4. 研究JET与模型压缩技术结合,进一步降低部署成本。
- 研究意义:1. 为LRMs高效推理提供新范式,缓解过度思考问题,降低计算资源消耗;2. 推动强化学习在推理优化中的应用,为平衡模型性能与效率提供实践参考;3. 启发认知科学与AI融合,促进类人高效推理模型的发展。
大模型的“过度思考”本质
受认知科学中“证据积累模型”(Evidence Accumulation Models)启发,研究团队发现:大模型在推理早期已积累足够信息,后续步骤多为冗余。实验显示,截断75%的推理链后,模型仍能保留90%的准确率;即使仅保留25%的推理步骤,准确率仍达46%(如图1右)。这表明,关键推理信息往往集中在初始阶段,冗余步骤是效率瓶颈。
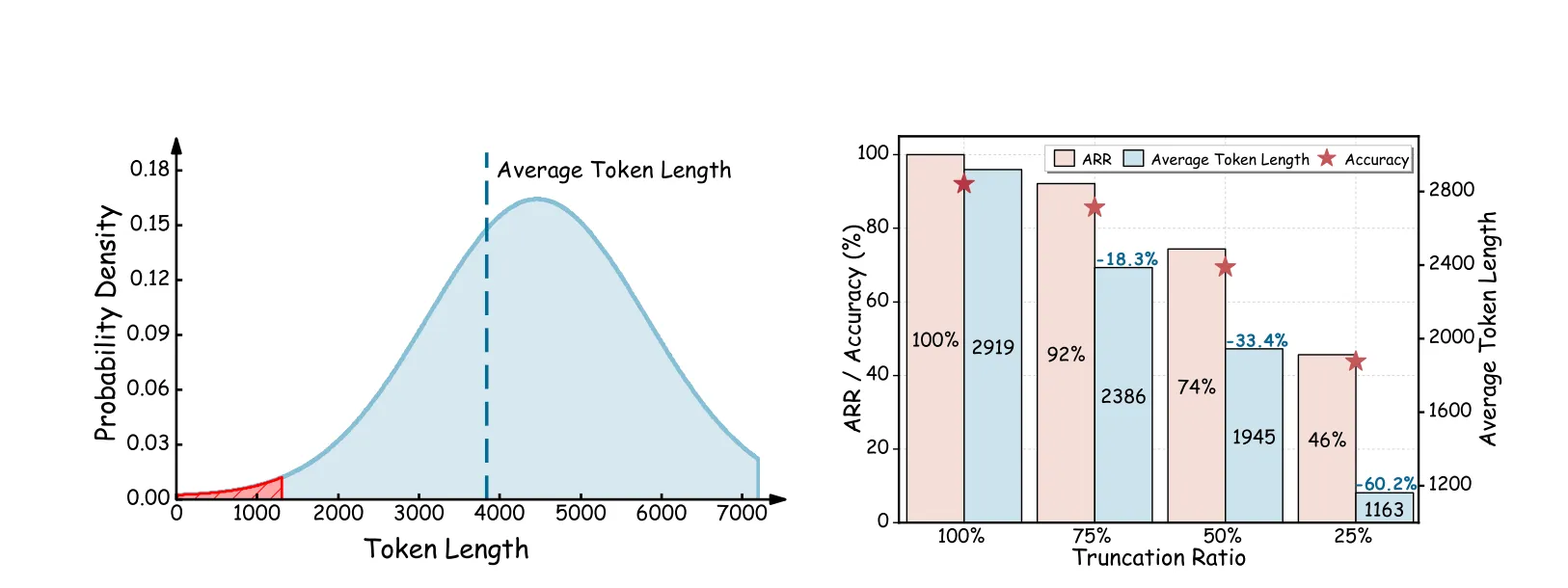
痛点:现有强化学习方法难以在采样阶段生成短推理链,导致训练数据分布失衡;人工压缩的推理链又与模型自然生成分布脱节,影响学习稳定性。并且“思考”越长,用于计算的花销也会越大,而过度思考未必能够更好的答案,又不能减少计算花销。
their deep reasoning often incurs substantial computational costs.
深度推理的计算花销很大
现有优化推理模型的两种方式
现有的优化推理模型的两种方式均是使模型进行不推理或者减少推理长度来进行的,一种是 自适应选择是否推理 和 长度奖励函数鼓励简洁推理。
it’s necessary to identify short, distributionally consistent reasoning trajectories from the model’s own long reasoning chains
有必要从模型自己的长推理链中识别出短的、分布一致的推理轨迹
自适应选择是否推理
自适应思维模式选择方法(adaptive thinking mode selection methods)通过有监督微调(SFT)为模型提供多种推理模式(思考/不思考),然后使用带有思维奖励的强化学习(RL)为每个问题选择最合适的模式。
📌 核心思想
并非所有问题都需要“思考链(chain-of-thought, CoT)”才能得出正确答案。
有些问题非常简单(如“2+2=?”),直接输出答案即可;而复杂问题(如“如果昨天是星期一,明天是几号?”)则需要模型展开推理。
因此,“自适应思维模式选择”让模型根据问题难度自动决定是否启用推理模式。
⚙️实现方法
- 多模式训练(SFT 阶段)
- 在监督微调(Supervised Fine-Tuning)阶段,模型被训练成拥有两种模式:
思考模式(Think Mode):输出详细推理链。
直答模式(Answer Mode):直接给出答案,不展示推理过程。
- 数据集里会标注出每个问题对应的模式。
- 强化学习(RL 阶段)
- 使用带有思维奖励(Thinking Reward)的强化学习进一步训练模型。
- 奖励机制会鼓励模型为复杂问题选择思考模式,为简单问题选择直答模式。
- 目标是最大化综合性能:既保持高正确率,又减少不必要的推理开销。
🧩 代表性工作
- DeepSeek-R1 / DeepSeek V2.5:在训练中引入了 adaptive reasoning mode。
- Think-on-Demand / Adaptive CoT:自动判断是否需要 CoT 的思维模式。
🚀 优点
- 显著减少平均推理长度(节省计算量)
- 在保证准确率的同时提升推理效率
- 有利于多任务模型在真实应用中动态调整计算资源
长度奖励函数鼓励简洁推理
📌 核心思想
长推理并不总是好事,虽然“思维链”能提高模型的正确率,但有时会出现冗长、重复或无效推理。因此,通过一个长度奖励函数,在训练中鼓励模型:
• 尽量用更短、更高效的推理过程;
• 避免啰嗦的 reasoning。
⚙️ 实现方法
1. 奖励函数设计
奖励 = 正确性分数 − λ × 推理长度
- λ 为惩罚系数,用于平衡“思维质量”和“思维长度”。
- 推理长度可用 token 数或思维步数衡量。
2. 训练方式
- 常与强化学习(RLHF 或 RLAIF)结合使用。
- 模型在学习如何“思考”的同时,被激励去“更快想明白”。
🧩 代表性工作
- OpenAI o1 / o1-mini:在强化学习阶段引入了长度惩罚项,使推理更加高效。
- Llama-Reasoner、DeepSeek-R1-LengthReward:都使用类似的 reward shaping 机制。
🚀 优点
- 显著减少平均 token 消耗
- 提升模型在有限计算预算下的推理速度
- 有助于提高“思维密度”,即单位 token 的推理质量
总结对比
| 方法 | 核心思路 | 实现方式 | 优点 | 代表模型 |
|---|---|---|---|---|
| 自适应是否推理 | 模型根据任务难度自动选择“思考/不思考”模式 | SFT + RL(带思维奖励) | 提高效率、保持准确率 | DeepSeek-R1, Adaptive CoT |
| 长度奖励函数 | 用奖励机制鼓励更短、更高效的推理 | RLHF/RLAIF + 长度惩罚项 | 减少推理冗余、节约token | OpenAI o1, DeepSeek-R1-LengthReward |
什么是JET方法?
By truncating trajectories during rollout, we can con- struct short reasoning paths that remain aligned with the model’s natural generation distribution.
JET(Just-Enough Thinking) 是一种训练大型推理模型(LRMs)主动终止冗余推理过程的方法,旨在提升推理效率的同时保持准确率。其核心思想是:LRMs在推理早期已积累足够信息,后续步骤往往冗余,因此需训练模型学会“适可而止”的推理策略。
JET通过轨迹截断和质量控制长度奖励,引导模型主动终止无效推理,核心设计如下:
两阶段轨迹采样:让模型“看见”短推理链
- 全轨迹生成(Stage 1):保留模型自然生成的完整推理链,作为基础数据。
- 渐进式截断(Stage 2):通过Progressive Early-Stopping(PES)策略,在全轨迹中按比例(如25%、50%、75%)截断,插入“停止思考”信号(如“已获得足够信息,最终答案为...”),生成不同长度的推理变体。此举既保持与模型生成分布的一致性,又增加短推理链样本多样性(如图2)。
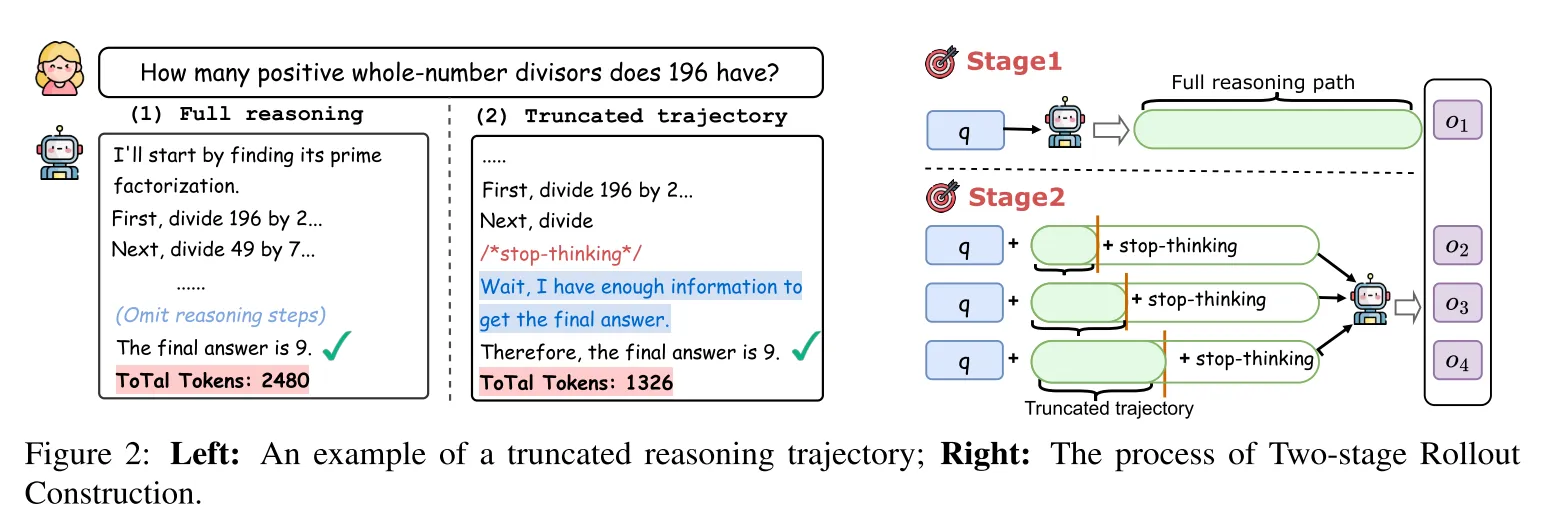
质量控制长度奖励:平衡准确率与简洁性
传统长度奖励仅惩罚长推理,可能导致“为短而短”的错误。JET设计质量控制长度奖励: 1. 仅对正确推理施加长度惩罚,确保准确率优先;2. 以同问题中最短正确推理为基准,对更长的正确推理按比例扣分,鼓励“最短正确路径”。
- 基础奖励
基于答案正确性(racc)和格式规范性(rf)。
- 长度奖励
对正确推理轨迹,以最短正确轨迹为基准,对较长轨迹施加长度惩罚,公式为:
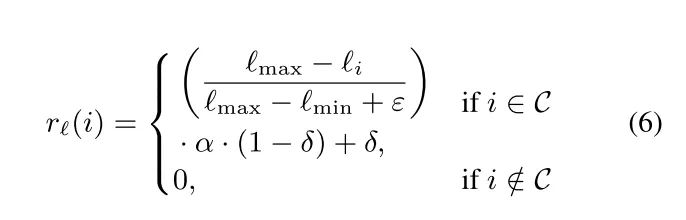
其中,C为正确轨迹集合,ℓmin / ℓmax 为最短/最长正确轨迹长度,α控制惩罚强度,δ确保正确轨迹获得最低奖励。
JET的核心优势
- 分布一致性:截断轨迹来自模型原生推理链,避免人工构造短轨迹导致的分布偏移。
- 效率与准确率平衡:通过动态截断和长度奖励,在减少推理步数(降低计算成本)的同时,保持甚至提升答案准确率。
- 泛化能力:在数学推理(如Olympiad、MATH500)和跨领域任务(如GPQA、MMLU)中均表现稳定,支持不同规模模型(如1.5B和7B参数)。
实验验证
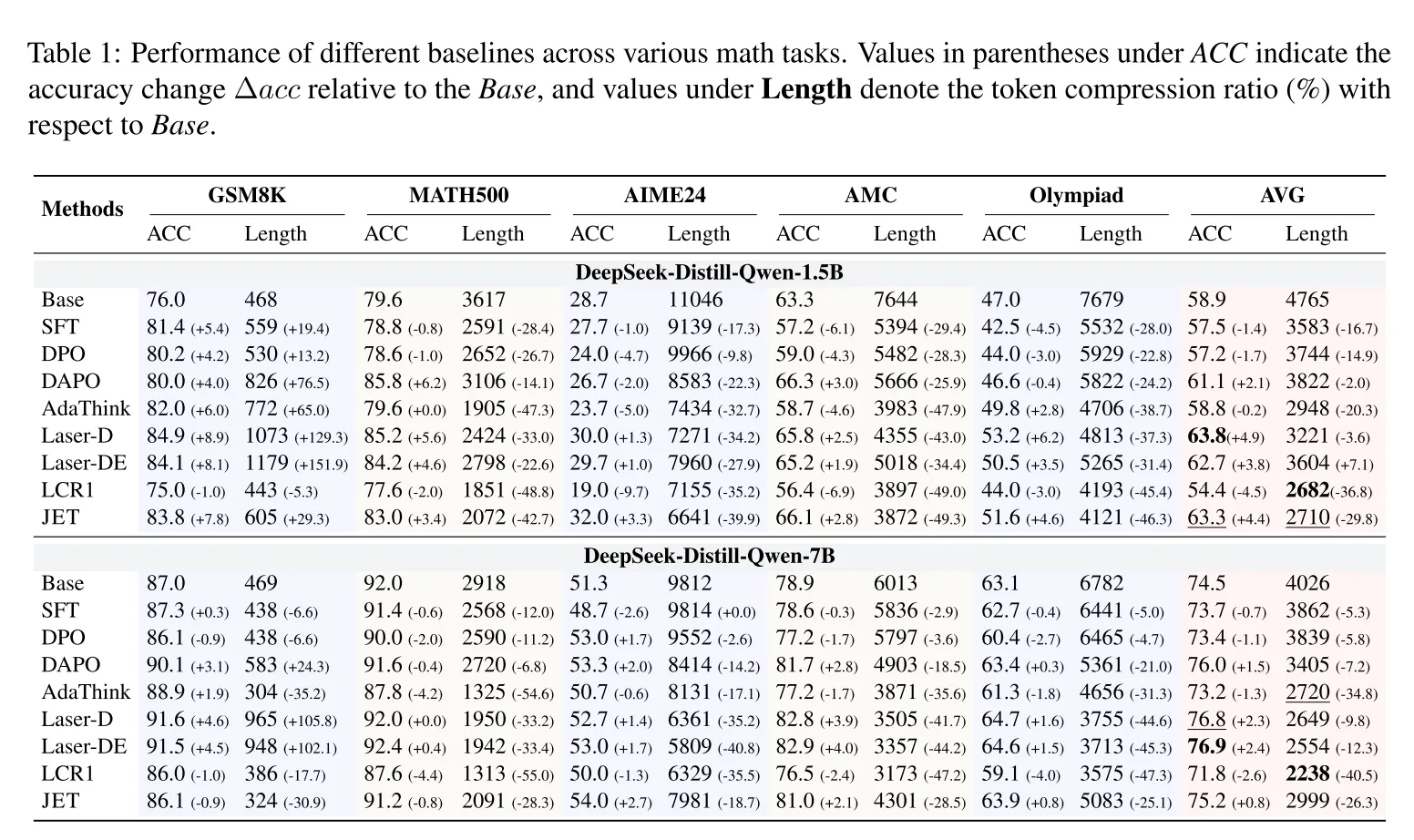
在数学推理(MATH500、AIME24)、竞赛题(Olympiad)等6项任务中,JET显著优于SFT、DPO、DAPO等基线方法:
小模型(1.5B):在Olympiad基准上,准确率提升4.6%(47.0%→51.6%),推理长度缩短46.3%(7679→4121 tokens);
大模型(7B):在AIME24竞赛题中,准确率提升2.7%(51.3%→54.0%),推理长度减少39.9%(11046→6641 tokens);
跨领域泛化:在常识推理(CSQA)、专业问题(GPQA-Diamond)等任务中,平均压缩率达39.7%,准确率保持稳定(表2)。
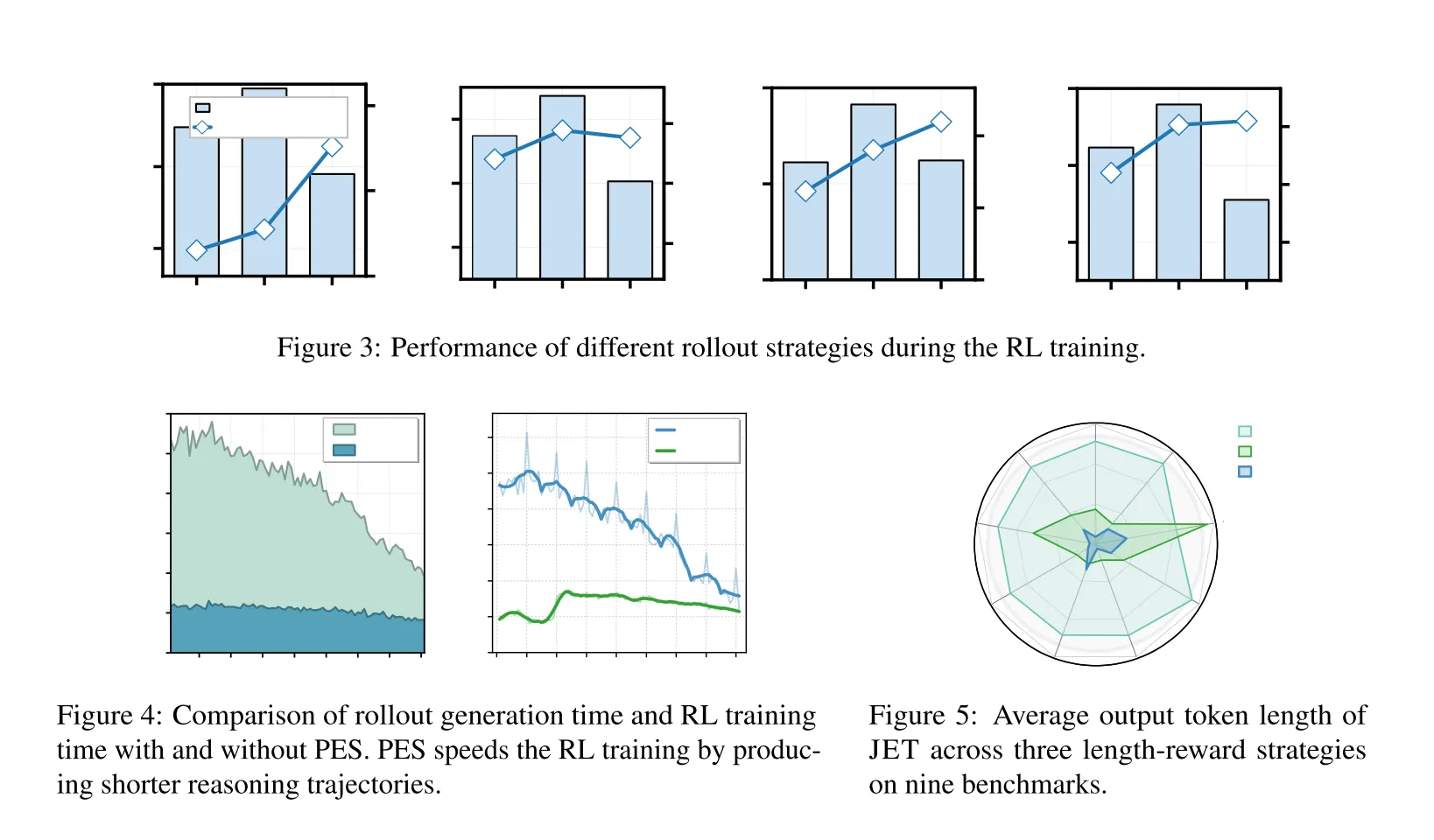
效率优势:PES策略使训练速度提升5倍,推理链截断减少了前向计算量,加速梯度更新(如图4)。
结论
JET揭示了大模型推理的一个核心矛盾——深度与效率的平衡。通过模拟人类“证据积累-阈值决策”的认知模式,JET让模型学会根据任务复杂度动态调整推理长度:简单问题少思考,复杂问题留足推理空间。这种“自适应资源分配”机制为下一代高效推理模型提供了新思路。
GitHub:https://github.com/JinyiHan99/Just-Enough-Think
支持DeepSeek-Distill-Qwen等模型微调。
推荐阅读: