文章来源:
https://arxiv.org/abs/2509.19012
文献速读
一、基本信息
- 标题:Pure Vision Language Action (VLA) Models: A Comprehensive Survey
- 作者:Dapeng Zhang, Jing Sun, Chenghui Hu*, Xiaoyan Wu, Zhenlong Yuan, Rui Zhou, Fei Shen†, and Qingguo Zhou†
- 关键词:Vision Language Action, Vision Language Model, Robotics, Embodied AI
二、文章概述
本文系统综述了视觉-语言-动作(VLA)模型的研究进展,将其定义为从传统策略控制向通用机器人技术的范式转变。文章提出了VLA方法的分类体系,包括自回归、扩散、强化学习、混合及专用方法,并分析了各类方法的动机、核心策略与实现细节。此外,还介绍了VLA研究的基础数据集、基准测试与仿真平台,最后探讨了当前挑战与未来方向,为VLA模型及通用机器人技术的发展提供了全面参考。
三、研究背景
传统机器人系统依赖预编程指令或特定任务策略,缺乏与人类及动态环境的有效交互。近年来,大语言模型(LLMs)和视觉-语言模型(VLMs)的发展为机器人操作提供了更灵活的语义理解能力,但现有研究多聚焦于基础模型或传统机器人方法,缺乏对纯VLA方法的系统性梳理。此外,VLA模型在数据稀缺、跨模态融合、实时推理及安全部署等方面仍面临挑战。因此,本文旨在通过综合分析300余篇最新研究,构建VLA方法的分类框架,总结现状并展望未来方向,以推动通用具身智能的发展。
四、研究思路
- 提出研究问题:VLA模型如何统一视觉、语言与动作生成,其核心范式与挑战是什么?
- 构建研究框架:将VLA方法分为自回归、扩散、强化学习、混合及专用方法,结合应用场景与技术细节展开分析。
- 选择研究方法:采用文献综述法,系统梳理近三年VLA领域的关键研究,重点分析模型架构、数据集、仿真平台及评估指标。
- 分析数据:整合现有数据集(如Open X-Embodiment)、仿真工具(如Isaac Gym)及基准测试,评估不同方法的泛化性与效率。
- 得出结论:总结VLA模型的优势与局限,提出数据多样性、跨模态融合、实时推理及安全部署等未来研究方向。
五、研究结果
- VLA模型通过统一框架实现视觉-语言-动作的端到端对齐,显著提升机器人在动态环境中的任务适应性。
- 自回归方法擅长长序列推理(如RT-2、PaLM-E),扩散模型优化动作平滑性(如Diffusion Policy),强化学习增强动态环境适应性(如SafeVLA)。
- 混合架构(如HybridVLA)结合多范式优势,平衡推理精度与动作生成质量,但计算成本较高。
- 现有数据集(如BridgeData、OXE)和仿真平台(如Habitat、CARLA)支撑了VLA模型的训练,但真实世界数据稀缺与仿真-现实差距仍是主要瓶颈。
六、研究结论、不足与展望
- 研究结论:VLA模型通过融合视觉-语言理解与动作生成,推动机器人从单一任务向通用智能发展。现有方法在跨模态对齐、复杂任务规划等方面取得进展,但数据稀缺、实时性不足及安全风险限制了实际部署。
- 研究的创新性:首次提出VLA方法的系统性分类框架,整合自回归、扩散、强化学习等范式;强调数据集与仿真平台对VLA发展的支撑作用;深入分析了VLA在机器人操作、自动驾驶等领域的应用潜力。
- 研究的不足之处:未涵盖VLA模型在多机器人协作中的应用;对真实世界部署中的伦理与安全问题讨论较浅;部分分类(如专用方法)的边界定义不够明确,可能导致交叉方法归类模糊。
- 研究展望:未来需构建更大规模、多模态的真实世界数据集;探索高效推理机制(如模型压缩、并行解码)以提升实时性;加强安全约束与人类反馈融合,确保VLA在开放环境中的可靠性;推动VLA与具身智能的深度结合,实现通用机器人系统。
- 研究意义:本文为VLA领域提供了首个全面综述,明确了研究脉络与核心挑战,为后续模型设计、数据集构建及应用落地提供了理论指导,助力推动通用人工智能在机器人领域的突破。
引言
- 痛点切入:传统机器人只会"重复劳动"?工厂机械臂、物流分拣机…这些"单项冠军"遇到新任务就"傻眼"。
they provide only cursory examinations of robotic models or concentrate primarily on foundational models
他们只提供机器人模型的粗略检查或主要集中在基础模型
- 转机出现:当视觉语言模型(VLM)不再满足于"被动描述",而是化身"主动执行者"——Vision Language Action(VLA)模型横空出世!
- 核心价值:这篇顶刊综述(arXiv:2509.19012)系统梳理了VLA的技术脉络,揭秘机器人如何通过"视觉-语言-动作"闭环,实现从"专用工具"到"通用助手"的跨越。
VLA:让机器人"能看懂、会理解、可行动"
Modern robots can “see” using computer vision models, “understand” language through large language models, and “act” via controllers or learned policies;
现代机器人可以使用计算机视觉模型“看”,通过大型语言模型“理解”语言,并通过控制器或学习策略“行动”;
- 传统机器人的瓶颈
- 依赖预编程指令,只能在固定场景完成单一任务(如工厂焊接)。
- 无法理解人类语言指令,更不能应对动态环境(如家庭中移动的宠物、突发的障碍物)。
- VLA的突破:三模态融合
- 视觉(Vision):"看见"环境(摄像头、传感器输入)。
- 语言(Language):"理解"指令(如"把红色杯子放到桌上")。
- 动作(Action):"执行"决策(规划机械臂轨迹、调整力度)。
- 关键优势:端到端打通"感知-推理-控制",无需人工拆解任务!
- 举个例子
当你说"倒一杯水",VLA模型会:- ① 视觉识别:定位水杯、水龙头、水面高度;
- ② 语言解析:理解"倒"的动作逻辑(拿起杯子→对准水龙头→控制水流→放回原位);
- ③ 动作生成:输出机械臂关节角度、力度等连续控制信号。

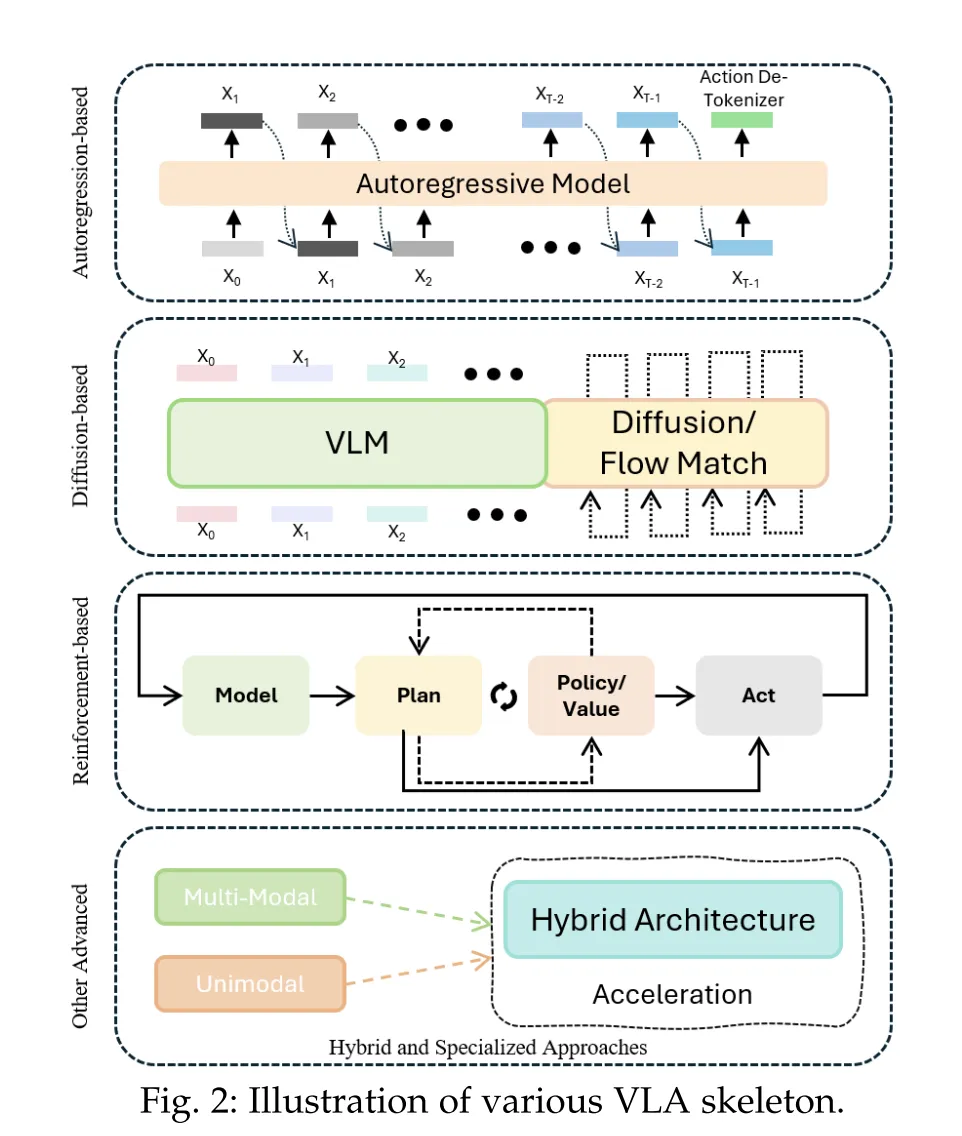
技术解密:VLA有哪些"门派"?
We classify VLA approaches into 4 categories: autoregression-based, diffusion-based, reinforcement-based, hybrid, and specialized methods, and provide a detailed analysis of their motivations, core strate- gies, and mechanisms.
我们将VLA方法分为4类:基于自回归的、基于扩散的、基于强化的、混合的和专门的方法,并详细分析了它们的动机、核心策略和机制。
| 方法类型 | 核心思路 | 代表模型 | 优势 |
|---|---|---|---|
| 自回归模型 | 像"写文章"一样逐帧生成动作序列 | RT-2、OpenVLA | 逻辑连贯,适合长流程任务(如组装) |
| 扩散模型 | 通过"去噪"生成多样化动作轨迹 | Diffusion Policy | 鲁棒性强,抗干扰(如手抖、光照变化) |
| 强化学习模型 | 从"试错"中学习最优动作(结合人类反馈) | SafeVLA、iRe-VLA | 适应动态环境,持续优化策略 |
通俗类比:
- 自回归模型 = 照着食谱一步步做菜;
- 扩散模型 = 面对多种食材,随机尝试组合直到做出美味;
- 强化学习模型 = 新手学开车,教练(反馈)越骂开得越好。
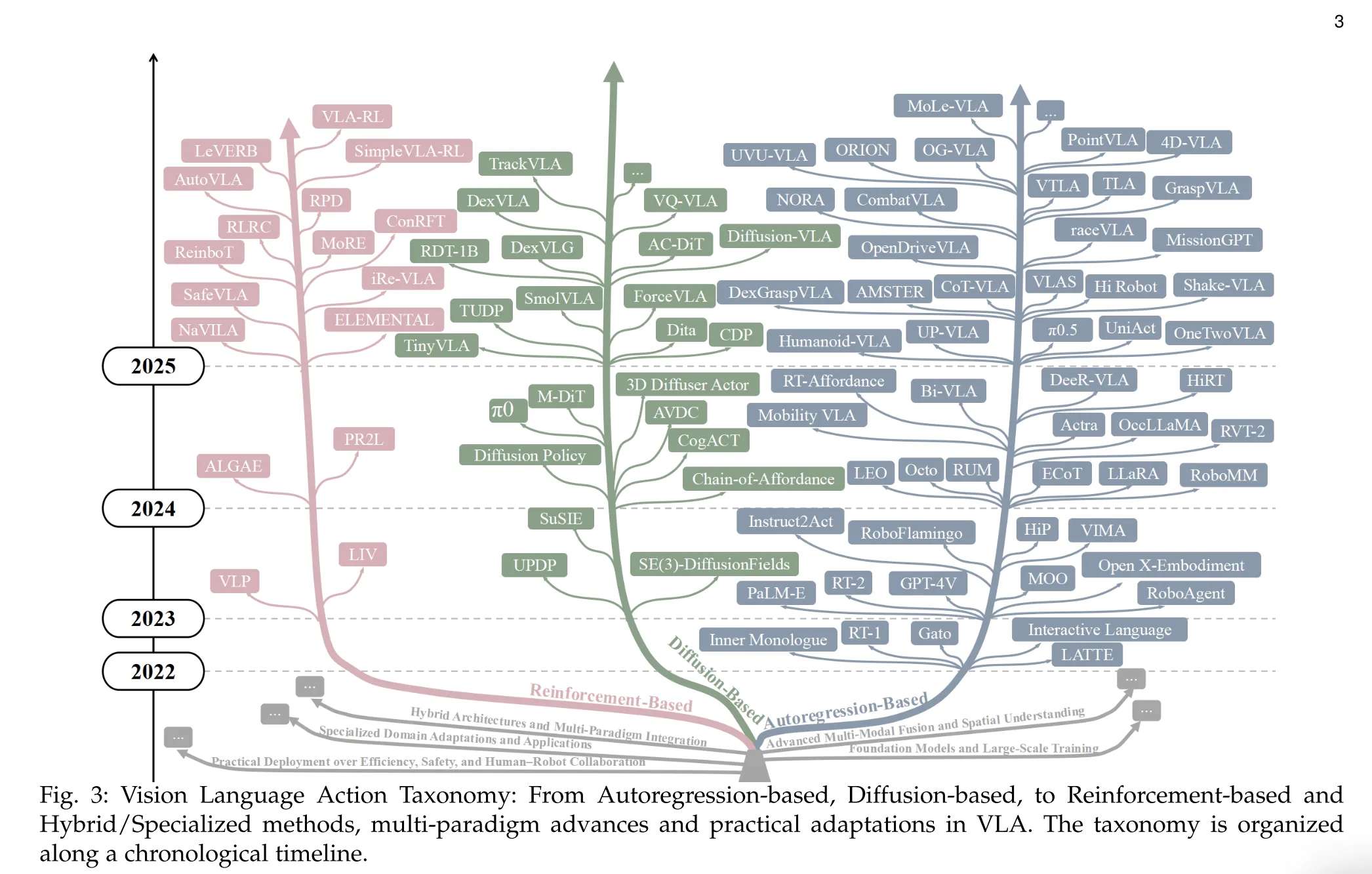
下图3:视觉语言动作分类:从基于自回归、基于扩散、到基于强化和混合/专用方法,VLA中的多范式进展和实际适应。分类法是按照时间顺序组织的。
VLA的"练兵场":数据、仿真与硬件
数据从哪来?
- 真实世界数据集:如Open X-Embodiment(16万+任务,覆盖10种机器人)、BridgeData(71个场景,从实验室到家庭)。
- 仿真数据:通过模拟器(如Isaac Gym、CARLA)生成海量标注数据,低成本解决"数据稀缺"问题。
仿真平台:机器人的"元宇宙"
- THOR/Habitat:模拟家庭环境,训练导航、抓取能力;

- CARLA:自动驾驶专用,生成雨天、堵车等极端场景数据。

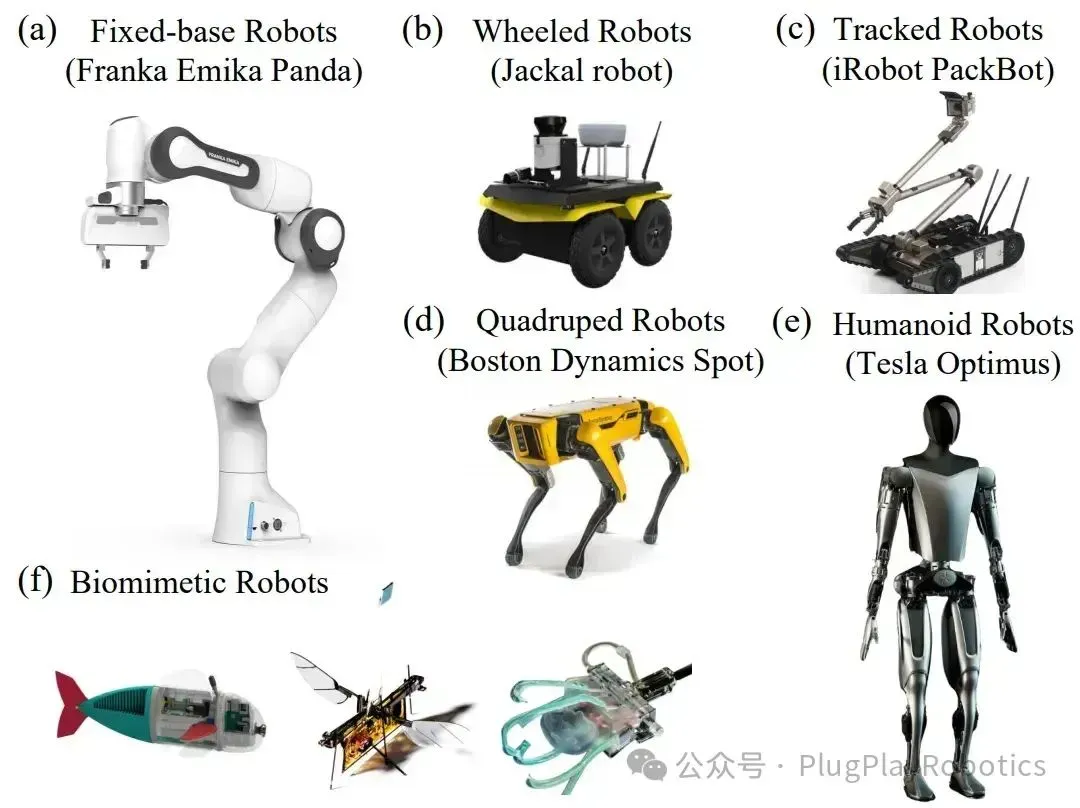
硬件载体
- 机械臂(Franka Emika)、人形机器人(Tesla Bot)、移动机器人(波士顿动力Atlas),甚至无人机、自动驾驶汽车!
未来已来?VLA的应用与挑战
落地场景
- 家庭服务:做饭、打扫、照顾老人(如RoboNurse-VLA完成高精度抓取);
- 工业制造:柔性生产线(同一机器人焊接、装配、质检);
- 危险作业:核泄漏处理、深海探测(代替人类进入极端环境)。
当前瓶颈(论文重点强调)
- 数据成本高:真实世界采集1小时机器人数据需上万元;
- 实时性不足:复杂任务推理耗时(如自动驾驶决策需毫秒级响应);
- 安全性风险:动作失误可能导致设备损坏或人员受伤(如抓取易碎品用力过猛)。
未来方向
- 更高效的模型:压缩参数(如TinyVLA仅需5%可训练参数)、加速推理(FAST动作 tokenization);
- 更安全的交互:引入"人类反馈强化学习(RLHF)",避免危险动作;
- 更通用的硬件适配:同一VLA模型适配机械臂、无人机、人形机器人等多种载体。
VLA离我们还有多远?
- 短期(3-5年):在结构化场景落地(如餐厅送餐机器人、工厂协作机器人);
- 长期(10年+):进入家庭,成为像"贾维斯"一样的全能助手。
- 论文价值:这篇综述整合了300+最新研究,为开发者提供"技术地图",加速VLA从实验室走向产业化。
最后,你最想让VLA机器人帮你做什么?评论区聊聊~
推荐阅读: