文献速读
一、基本信息
- 标题:ReconDreamer: Crafting World Models for Driving Scene Reconstruction via Online Restoration
- 作者:Chaojun Ni, Guosheng Zhao, Xiaofeng Wang, Zheng Zhu, Wenkang Qin, Guan Huang, Chen Liu, Yuyin Chen, Yida Wang, Xueyang Zhang, Yifei Zhan, Kun Zhan, Peng Jia, Xianpeng Lang, Xingang Wang, Wenjun Mei
- 关键词:动态驾驶场景重建;世界模型;在线修复;渐进式数据更新;大 maneuver 渲染
二、文章概述
闭环仿真对端到端自动驾驶至关重要,但现有基于NeRF和3DGS的传感器仿真方法在渲染新轨迹(如变道)时存在不足。虽有研究通过整合世界模型知识缓解该问题,但复杂 maneuver(如多车道偏移)的精确表示仍具挑战。本文提出ReconDreamer,通过增量整合世界模型知识增强驾驶场景重建,包括DriveRestorer在线修复伪影及渐进式数据更新策略,以确保复杂 maneuver 的高质量渲染,是首个有效渲染大 maneuver 的方法。
三、研究背景
开环仿真技术在自动驾驶领域进步显著,但当前开环评估方法难以准确评估端到端规划算法,需更鲁棒的闭环评估框架,这要求驾驶场景表示能重建复杂动态环境。闭环仿真依赖NeRF和3DGS等场景重建方法,然这些技术受训练数据密度和多样性限制,渲染能力局限于与训练数据分布相近的场景,在复杂、高变化驾驶 maneuver 中表现不佳。自动驾驶世界模型能生成符合特定驾驶指令的多样化视频,为闭环仿真带来新可能,DriveDreamer4D证明利用预训练世界模型可提升动态驾驶场景重建质量,但在大 maneuver 渲染上仍存挑战。
四、研究思路
- 提出研究问题:现有基于世界模型的方法(如DriveDreamer4D)在大 maneuver(如多车道偏移)渲染中存在伪影和质量问题,需解决复杂轨迹下的动态场景重建精度。
- 构建研究框架:设计ReconDreamer框架,包括动态场景重建模型、DriveRestorer修复模块及渐进式数据更新策略(PDUS),通过迭代优化实现大 maneuver 渲染。
- 选择研究方法:基于3D高斯 splatting 等动态场景重建技术,结合世界模型知识,提出DriveRestorer(基于扩散去噪过程)修复渲染伪影,PDUS渐进扩展轨迹生成训练数据。
- 分析数据:在Waymo数据集的8个高交互场景上实验,与PVG、S3Gaussian等方法比较NTA - IoU、NTL - IoU、FID等指标,并进行用户研究评估渲染质量。
- 得出结论:ReconDreamer通过在线修复和渐进式数据更新,在大 maneuver 渲染上超越现有方法,验证了增量整合世界模型知识的有效性。
五、研究结果
- ReconDreamer在NTA - IoU、NTL - IoU和FID上优于Street Gaussians,相对提升分别为24.87%、6.72%和29.97%。
- 在大 maneuver 渲染中,ReconDreamer超越DriveDreamer4D(PVG),NTA - IoU相对提升195.87%,用户研究中平均胜率达96.88%。
- DriveRestorer有效减轻新轨迹渲染中的伪影,结合掩码策略增强对天空和远景等困难区域的修复。
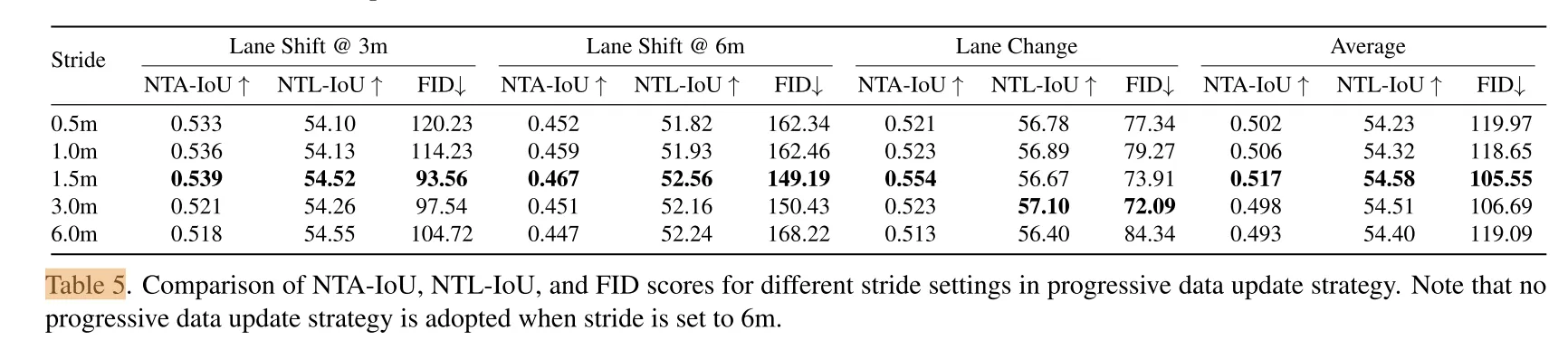
- 渐进式数据更新策略(PDUS)通过逐步扩展轨迹提升大 maneuver 渲染质量,步长设为1.5m时性能最优。
- 不同骨干网络对比显示,基于DriveDreamer - 2并结合掩码的DriveRestorer修复效果最佳,NTA - IoU达0.517,FID降至105.55。
六、研究结论、不足与展望
- 研究结论:ReconDreamer通过DriveRestorer在线修复伪影和渐进式数据更新策略,有效提升动态驾驶场景重建质量,尤其在大 maneuver(如6米车道偏移)渲染上表现突出,超越现有方法,为闭环仿真提供更鲁棒的场景表示。
- 研究的创新性:首次实现大 maneuver(达6米)的有效渲染;提出DriveRestorer通过在线修复减轻伪影;设计PDUS渐进更新训练数据,降低视频修复复杂度。
- 研究的不足之处:依赖预训练世界模型和3D检测/HDMap数据,在无结构化道路或极端天气场景适应性未验证;PDUS步长和掩码策略需手动调整,缺乏自适应机制;修复模块训练需大量退化数据对,数据集构建成本较高。
- 研究展望:探索无监督/自监督方式构建修复数据集,减少对标注数据依赖;优化PDUS自适应调整轨迹扩展步长和数据权重,提升复杂场景泛化能力;结合多模态输入(如激光雷达点云)增强动态场景几何约束,进一步提升重建精度;将方法扩展至更复杂动态环境,如交通拥堵、行人密集区域等。
- 研究意义:推动动态驾驶场景重建技术发展,为自动驾驶闭环仿真提供高质量场景表示;验证世界模型知识增量整合在复杂任务中的有效性,为其他动态场景重建任务提供借鉴;提升自动驾驶系统在极端或未见过场景的仿真能力,加速安全验证和算法迭代。
现有的驾驶场景存在问题
现有动态驾驶场景重建方法(如NeRF、3DGS)依赖与训练数据分布高度相似的条件,在渲染大幅机动场景(如多车道变换)时存在显著缺陷,表现为:
- 鬼影 artifacts(如天空和远景区域的模糊或异常斑点)

- 时空一致性差(车道线扭曲、前景车辆变形或缺失)

- 大视角偏移失效(如6米车道偏移时渲染质量急剧下降)

ReconDreamer的核心创新
通过提出增量式世界模型知识融合框架,通过以下模块解决场景生成问题:
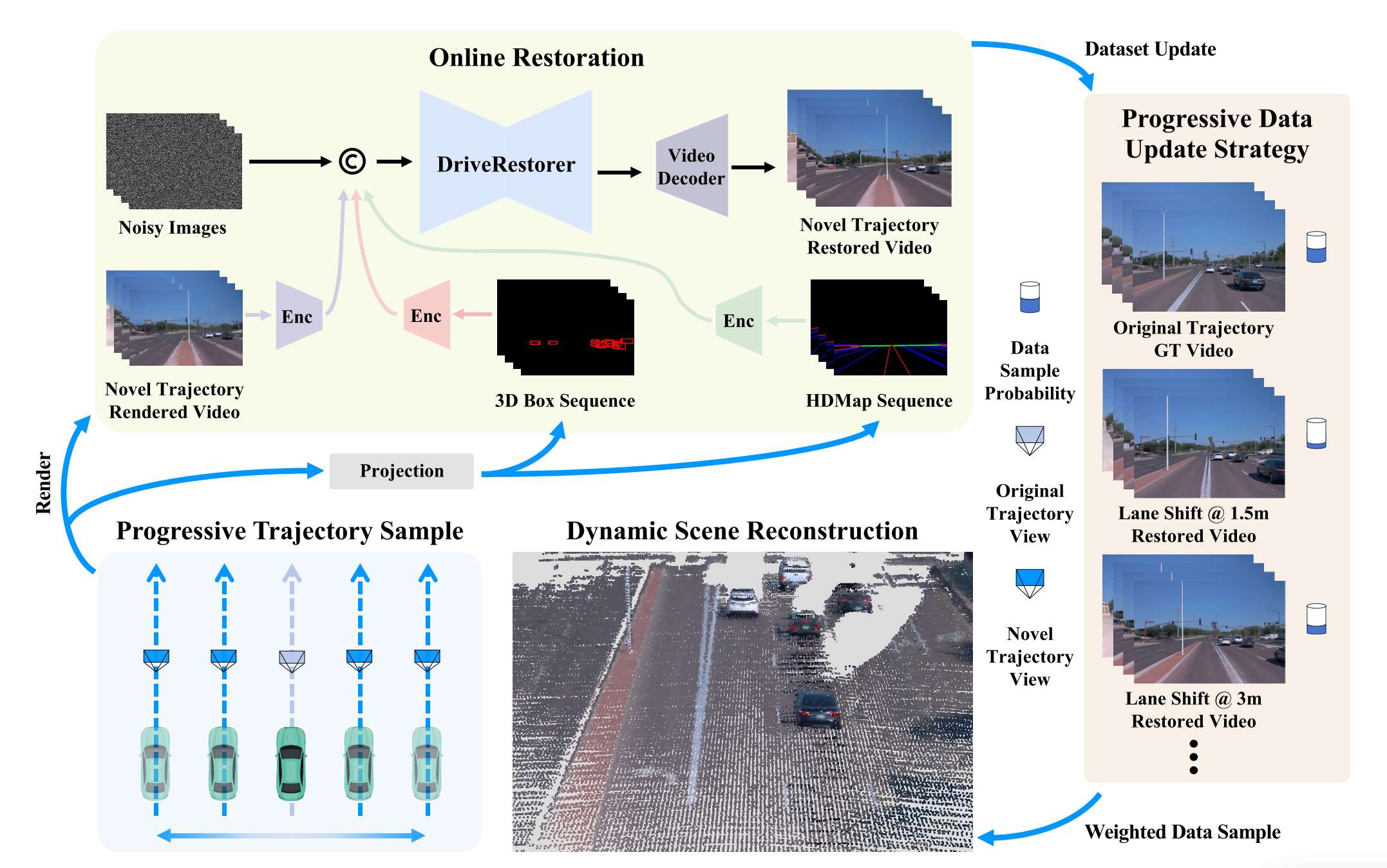
DriveRestorer:在线修复网络
- 功能:基于世界模型(如DriveDreamer-2)微调,通过在线修复减轻渲染伪影。
- 技术细节:
构建退化视频数据集(训练过程中不同阶段的渲染结果),结合3D框和HDMap作为结构条件,确保交通元素的时空一致性。
引入掩码策略,重点修复天空、远景等挑战性区域(图3、7)。


- 效果:相比Stable Diffusion等基线,NTA-IoU提升9.42%,FID降低15.84%(表4)。

Progressive Data Update Strategy (PDUS):渐进式数据更新策略
- 功能:
逐步扩展新颖轨迹(如从1.5米到6米车道偏移),降低视频修复复杂度,实现大机动场景的高质量渲染。
- 技术细节:
按步长(如1.5米)递增生成新颖轨迹,经DriveRestorer修复后用于优化场景重建模型(算法1)。

通过加权采样动态平衡原始数据与修复数据,避免训练不稳定。
- 效果:步长设为1.5米时性能最优,相比无渐进策略(步长6米),NTA-IoU提升4.87%,FID降低11.4%(表5)。
微调DriveDreamer-2的实现方式
ReconDreamer通过以下步骤基于世界模型(如DriveDreamer-2)微调并实现在线修复,以减轻渲染伪影:
修复数据集构建
- 退化视频生成:
训练一个未充分收敛的动态场景重建模型(如3D高斯溅射模型),在训练过程中按阶段渲染原始轨迹的视频,得到含伪影的退化视频(如天空区域模糊、远景失真)。
- 数据对构建:
将退化视频与原始轨迹的真实视频(GT)配对,形成修复数据集,用于训练DriveRestorer。
DriveRestorer设计与微调
- 基础模型:
基于DriveDreamer-2(一种支持结构化条件控制的世界模型)构建DriveRestorer,其核心为扩散去噪网络。
- 结构化条件输入:
整合3D边界框序列、高精地图(HDMap)序列及新轨迹信息,通过投影变换与新视角对齐,确保交通元素(如车辆、车道线)的时空一致性。
- 掩码策略:
对退化视频中伪影严重的区域(如天空与远景)施加掩码,强制模型优先修复这些区域。

- 微调目标:
通过扩散损失(公式2)优化模型,最小化修复视频与GT的差异,具体为:
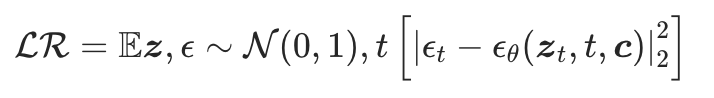
是基于扩散模型的去噪损失函数。其中,Et为时间步(t)的随机噪声,(C)包含退化视频、3D框及HDMap等条件。
这个函数损失在干啥?
模型要学会猜出在第 t 步加到图像上的噪声是多少。
在线修复流程
- 动态场景重建模型渲染:
使用当前训练阶段的重建模型(如Street Gaussians)渲染新轨迹视频,得到含伪影的初始结果: Vnovel
- 实时修复:
将Vnovel输入预训练的DriveRestorer,结合结构化条件(3D框、HDMap)进行在线去伪影,输出修复后的视频Vnovel。
渐进式数据更新策略(PDUS)
- 轨迹扩展:
逐步增加新轨迹的横向偏移距离(如从1.5m到6m),避免一次性引入过大视角变化导致修复难度激增。
- 加权数据融合:
将修复后的新轨迹视频与原始视频按权重融合(权重随训练阶段递增),用于迭代优化重建模型,直至收敛。
推荐阅读: