用DeepSeek RAG快速搭建离线企业级专属知识库,数据安全+智能问答双赢
导语
“还在为员工找不到内部文档发愁?担心公开AI泄露企业机密?DeepSeek RAG私有化解决方案,3步构建安全高效的离线智能知识库,让企业数据‘活起来’!”
1. 痛点场景:企业知识管理的三大难题
-
场景1:新员工面对海量文档无从下手,培训成本高
-
场景2:客户咨询重复问题,客服响应效率低
-
场景3:使用公开AI存在数据泄露风险,合规压力大
“知识库不是文件的堆砌,而是需要能被‘唤醒’的智能资产。”
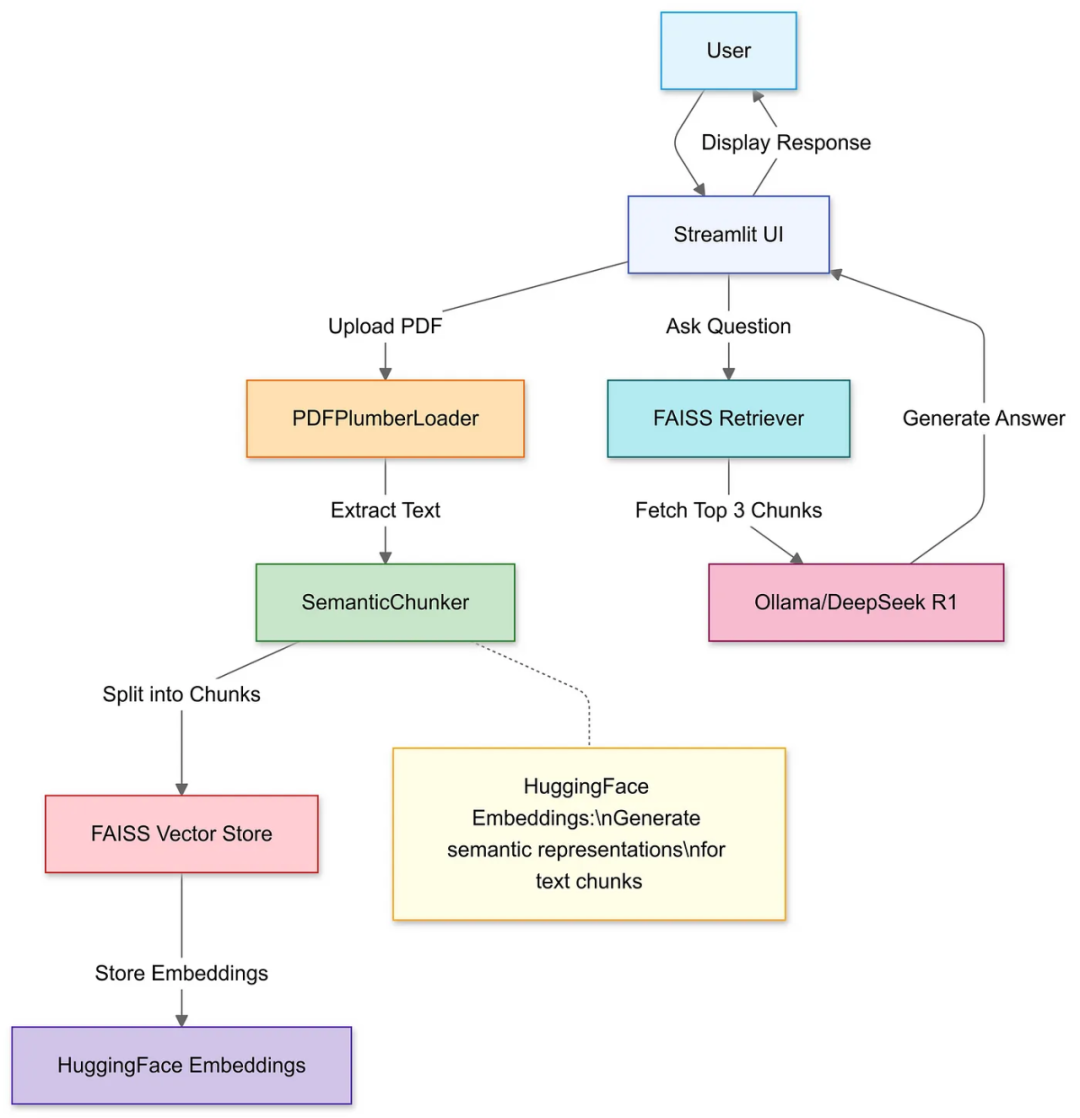
2. 技术解析:DeepSeek RAG如何实现“私有化+智能化”?
(配图:技术架构简图)
- RAG核心优势:检索增强生成 = 精准数据检索 + 自然语言生成
- 检索层:向量化技术秒级匹配企业文档(合同/手册/代码等)
- 生成层:DeepSeek大模型生成符合企业风格的答案
- 私有化亮点:
- 数据不出内网:本地化部署,0数据外传
- 灵活定制:支持行业术语微调,适配金融/法律/医疗等场景
- 低成本运维:一键更新知识库,无需重新训练模型
3. 三步搭建指南:从0到1构建专属知识库
-
Step1 安装Ollama:
Ollama 是一个开源的本地大语言模型(LLM)运行框架,主要功能是帮助用户在本地设备上轻松部署和运行大型语言模型。无需依赖云服务,从而确保数据隐私和安全。除了文本生成,Ollama 还支持图像生成等多模态应用。
- 选择对应的系统下载并安装Ollama
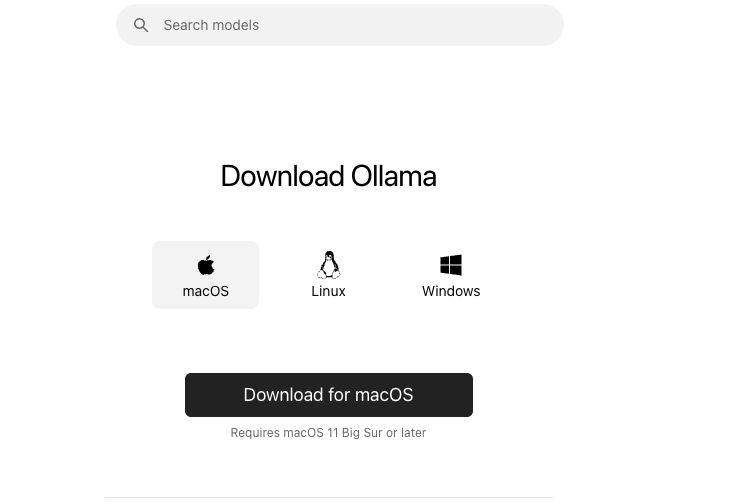
-
Step2 选择Deepseek-R1模型:
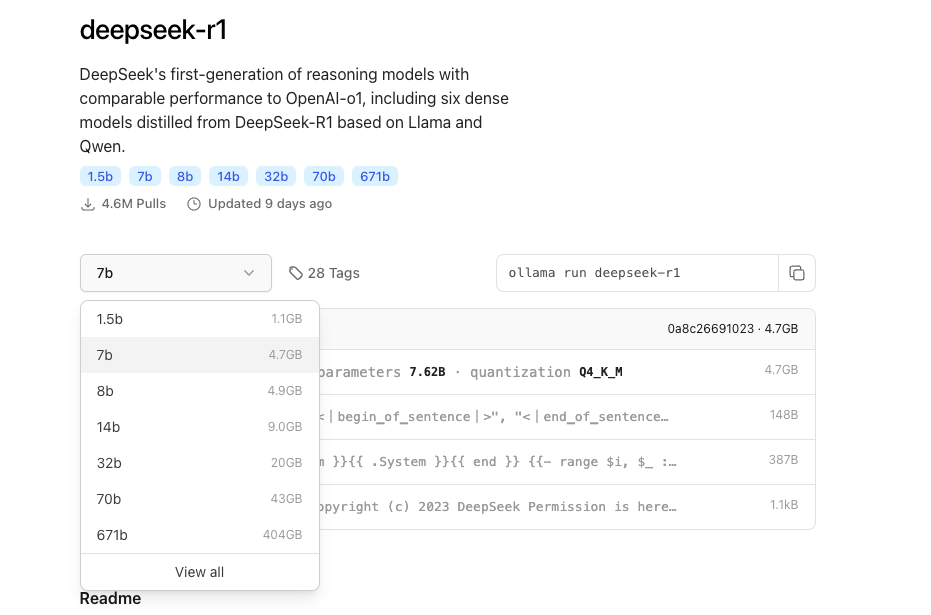
-
选择需要的参数模型
-
例如需要的7B的模型则直接在终端输入命令(模型文件4.7GB大小)
ollama run deepseek-r1:7b
下载完成后:
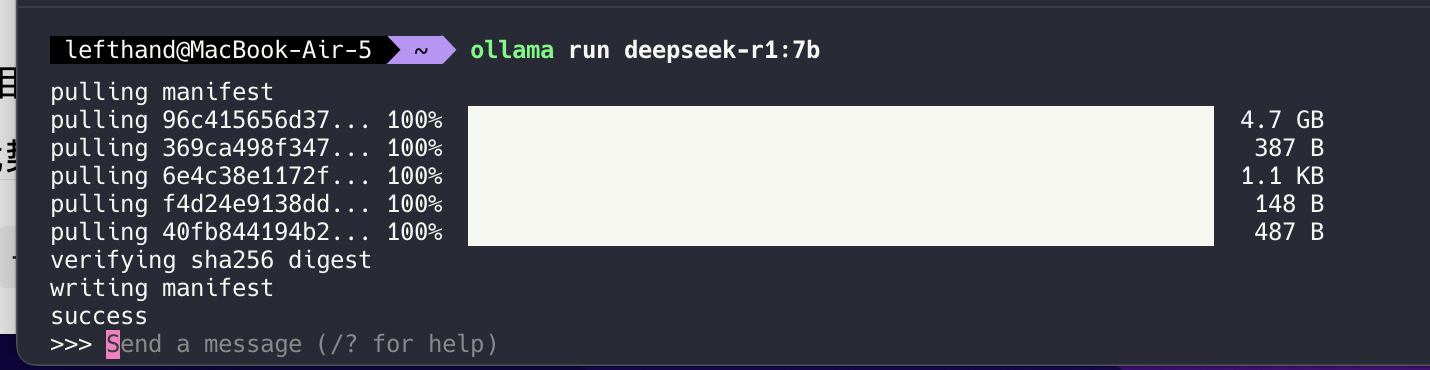
- 构建私有知识库:
-
-
库介绍
-
LangChain:文档处理与检索。
-
Streamlit:提供交互式Web界面。
-
-
python代码(创建RAG.py)
import os
import streamlit as st
from langchain_community.document_loaders import DirectoryLoader, PyPDFLoader, Docx2txtLoader, TextLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.chains import RetrievalQA
from langchain.prompts import PromptTemplate
from langchain_huggingface import HuggingFaceEmbeddings #
from langchain_community.vectorstores import Chroma
from langchain_community.llms import Ollama
import time
os.environ["HF_HUB_DISABLE_SSL_VERIFY"] = "1"
os.environ["TRANSFORMERS_OFFLINE"] = "1"
# 配置参数
DOC_DIR = "./knowledge_base"
EMBED_MODEL = "sentence-transformers/all-miniLM-L6-v2"
CHUNK_SIZE = 1000
CHUNK_OVERLAP = 200
OLLAMA_MODEL = "deepseek-r1:7b"
OLLAMA_BASE_URL = "http://localhost:11434"
# 初始化本地Ollama模型
def init_local_llm():
return Ollama(
base_url=OLLAMA_BASE_URL,
model=OLLAMA_MODEL,
temperature=0.1,
num_ctx=2048
)
# 文档处理与向量库构建
@st.cache_resource
def init_knowledge_base():
try:
# 创建多个加载器分别处理不同类型的文件
pdf_loader = DirectoryLoader(DOC_DIR, glob="**/*.pdf", loader_cls=PyPDFLoader, silent_errors=False)
docx_loader = DirectoryLoader(DOC_DIR, glob="**/*.docx", loader_cls=Docx2txtLoader,
silent_errors=False)
txt_loader = DirectoryLoader(DOC_DIR, glob="**/*.txt", loader_cls=TextLoader, silent_errors=False)
documents = []
# 加载每个格式的文件
documents.extend(pdf_loader.load())
documents.extend(docx_loader.load())
documents.extend(txt_loader.load())
# 文本分割
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=CHUNK_SIZE,
chunk_overlap=CHUNK_OVERLAP
)
texts = text_splitter.split_documents(documents)
# 创建向量库
embeddings = HuggingFaceEmbeddings(model_name=EMBED_MODEL)
vectordb = Chroma.from_documents(
documents=texts,
embedding=embeddings,
persist_directory="./chroma_db" # 添加持久化存储
)
return vectordb
except Exception as e:
st.error(f"文档加载失败:{str(e)}")
st.stop()
# 构建QA Chain
def create_qa_chain(vectordb):
llm = init_local_llm()
prompt_template = """基于以下上下文信息,请用中文给出专业、准确的回答。如果无法从上下文中得到答案,请说明原因。
上下文:
{context}
问题:{question}
答案:"""
PROMPT = PromptTemplate(
template=prompt_template,
input_variables=["context", "question"]
)
return RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=vectordb.as_retriever(
search_type="mmr", # 使用最大边际相关性搜索
search_kwargs={"k": 5}
),
chain_type_kwargs={"prompt": PROMPT},
return_source_documents=True
)
# Streamlit界面(添加异常处理)
def main():
st.title("DeepSeek RAG 知识库问答系统(本地优化版)")
st.markdown(f"📁 文档目录:`{DOC_DIR}`")
if "messages" not in st.session_state:
st.session_state.messages = []
# 显示历史消息
for message in st.session_state.messages:
with st.chat_message(message["role"]):
st.markdown(message["content"])
if "sources" in message:
with st.expander("参考文档"):
for doc in message["sources"]:
st.caption(f"📑 {os.path.basename(doc.metadata['source'])}")
st.code(doc.page_content[:300] + "...", language="text")
# 处理用户输入
if prompt := st.chat_input("请输入问题"):
st.session_state.messages.append({"role": "user", "content": prompt})
with st.chat_message("user"):
st.markdown(prompt)
try:
with st.spinner("正在检索知识库..."):
vectordb = init_knowledge_base()
qa_chain = create_qa_chain(vectordb)
result = qa_chain({"query": prompt})
# 使用 `st.empty()` 创建占位符进行流式输出
with st.chat_message("assistant"):
message_placeholder = st.empty() # 占位符
answer = result["result"]
message_placeholder.markdown(answer) # 立即显示完整的答案
with st.expander("来源文档"):
for doc in result["source_documents"]:
st.caption(f"📑 {os.path.basename(doc.metadata['source'])}")
st.code(doc.page_content[:300] + "...", language="text")
# 将答案及来源文档记录到会话状态
st.session_state.messages.append({
"role": "assistant",
"content": result["result"],
"sources": result["source_documents"]
})
except Exception as e:
st.error(f"处理失败:{str(e)}")
st.session_state.messages.pop() # 移除未回答的问题
if __name__ == "__main__":
main()- 依赖安装
pip install langchain streamlit chromadb pypdf sentence-transformers ollama langchain-community- 导入知识库
在项目路径下创建一个
knowledge_base文件夹,然后把对应的pdf或者其他文本文件放入
- 运行项目
streamlit run RAG.py运行项目之后会自动打开webUI界面,提问过程如下:
- 部分结果展示


注意事项
- 若
sentence-transformers/all-miniLM-L6-v2模型下载失败,可以手动下载模型
huggingface-cli download sentence-transformers/all-miniLM-L6-v2- 后续的项目代码也会对应更新到Github仓库中,并持续进行更新
- 仓库地址:
https://github.com/zgx949/Deepseek-RAG
扫描二维码,在手机上阅读
推荐阅读:
收藏