主页链接:https://miv-xjtu.github.io/FSDrive.github.io/
文献速读
| 一、基本信息 | 标题 | FutureSightDrive: Thinking Visually with Spatio-Temporal CoT for Autonomous Driving | |
|---|---|---|---|
| 作者 | Shuang Zeng, Xinyuan Chang, Mengwei Xie, Xinran Liu, Yifan Bai, Zheng Pan, Mu Xu, Xing Wei | ||
| 二、文章概述 | 本文提出了基于时空思维链(CoT)的自动驾驶框架FSDrive,使视觉语言模型(VLM)能进行视觉思考。通过中间图像形式的推理步骤统一未来场景生成和感知结果,消除跨模态转换的语义差距,建立端到端的视觉推理管道。提出统一的预训练范式和渐进式生成方法,实验结果证明了该方法在轨迹规划、未来帧生成和场景理解任务中的有效性,推动自动驾驶向视觉推理发展。 | ||
| 三、研究背景 | 多模态大语言模型(MLLMs)在自动驾驶领域应用广泛,端到端的视觉 - 语言 - 动作(VLA)模型简化了系统架构。然而,现有的自动驾驶方法通常采用离散文本CoT,这是对视觉信息的高度抽象和符号化压缩,可能导致时空关系模糊、细粒度信息丢失和模态转换间隙。受人类驾驶员认知机制启发,作者提出更直观的时空CoT方法,避免文本抽象过程中的信息损失,建立端到端的视觉推理管道。此外,现有的视觉生成方法存在缺乏语义信息、训练成本高的问题,因此作者提出了新的预训练范式和生成方法。 | ||
| 四、研究思路 | 提出研究问题 | 现有自动驾驶中离散文本CoT存在时空关系模糊、信息损失等问题,思考是否能以更接近现实模拟和想象的方式建模自动驾驶。 | |
| 构建研究框架 | 提出FSDrive框架,包括统一的视觉生成和理解预训练范式、时空CoT推理方法。 | ||
| 选择研究方法 | 基于现有MLLM,扩展词汇表,采用渐进式生成方法,通过实验验证方法有效性。 | ||
| 分析数据 | 在nuScenes和DriveLM等数据集上进行实验,分析轨迹规划、未来帧生成和场景理解的结果。 | ||
| 得出结论 | 根据实验结果,证明FSDrive方法能有效提升自动驾驶的视觉推理能力。 | ||
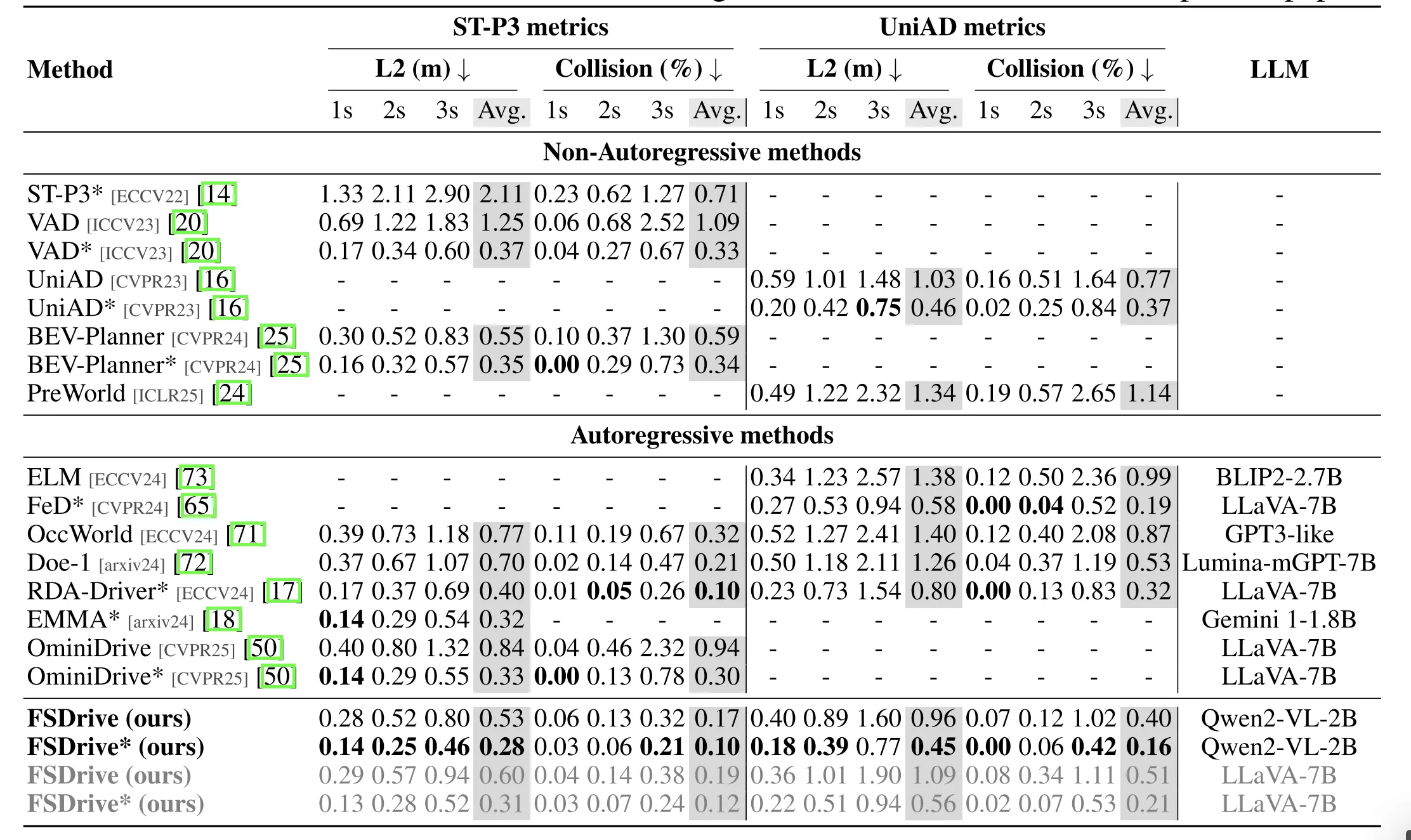
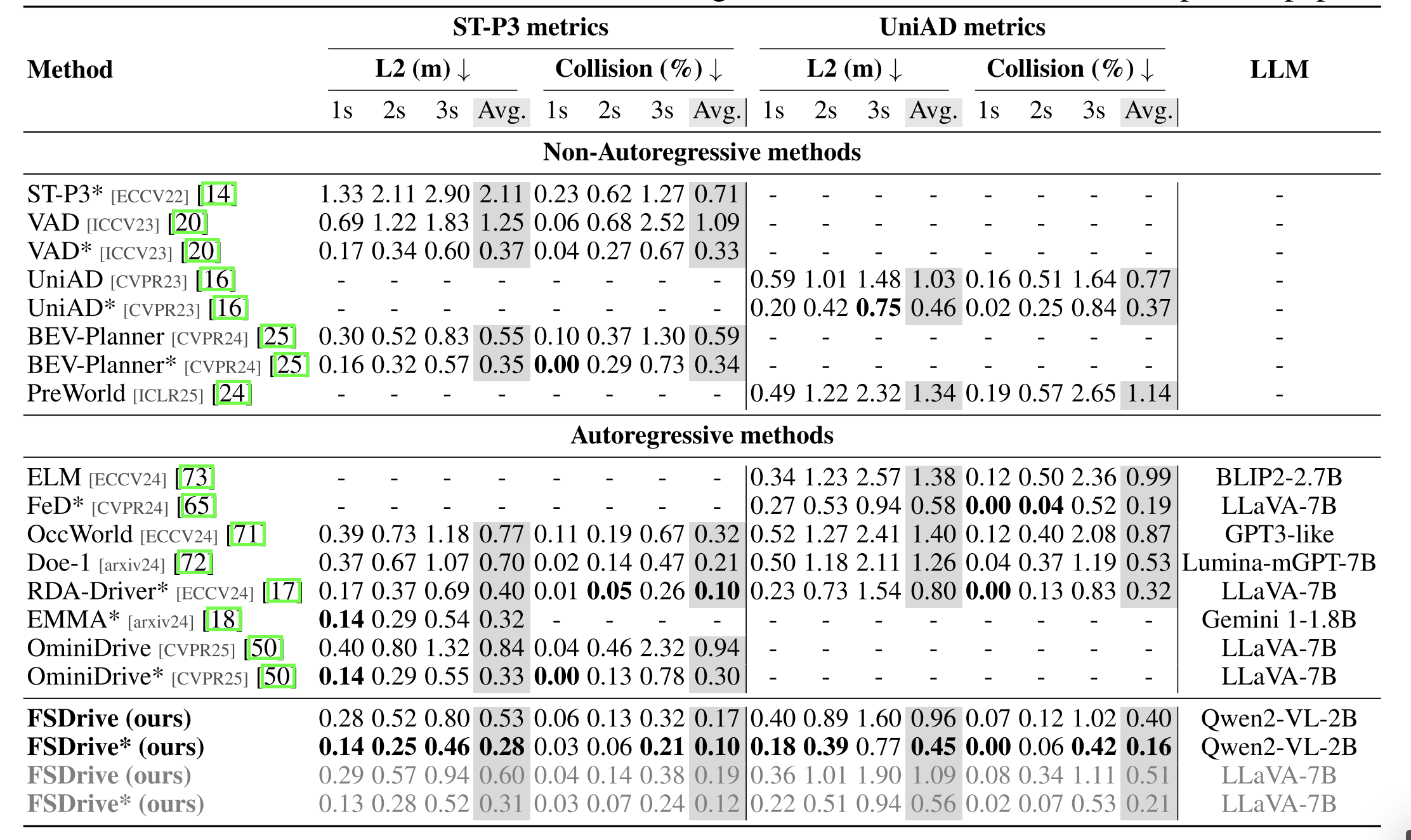
| 五、研究结果 | 轨迹规划方面,FSDrive在使用或不使用自我状态时,均优于先前的SOTA方法。 | ||
| 未来帧生成方面,FSDrive在FID指标上表现有竞争力,能以较少数据解锁MLLM的视觉生成能力。 | |||
| 场景理解方面,FSDrive在DriveLM数据集上的得分高于近期方法。 | |||
| 消融实验表明,统一的预训练范式和时空CoT能有效提升性能。 | |||
| 六、研究结论、不足与展望 | 研究结论 | 本文提出的FSDrive框架通过时空CoT使VLM能进行视觉思考,统一未来场景生成和感知结果,消除跨模态语义差距,建立端到端视觉推理管道。实验证明该框架在轨迹规划、未来帧生成和场景理解任务中有效,推动自动驾驶向视觉推理发展。 | |
| 研究的创新性 | 提出时空CoT推理方法,统一图像形式的推理;提出统一预训练范式,结合语义理解和视觉生成;采用渐进式生成方法,符合物理规律。 | ||
| 研究的不足之处 | 目前仅生成前视图的未来帧,未考虑全向视图,可能影响自动驾驶对周围环境的感知。 | ||
| 研究展望 | 未来可尝试生成全向视图的未来帧,以实现更安全的自动驾驶。同时,需关注LLMs在自动驾驶中的伦理挑战,推动技术和监管发展。 | ||
| 研究意义 | 建立了端到端的视觉推理管道,消除跨模态转换的语义差距,有效提升了自动驾驶在轨迹规划、未来帧生成和场景理解方面的性能,为自动驾驶向视觉推理发展提供了新方法。 |
背景与动机
- 背景:
多模态大语言模型(MLLMs)在自动驾驶中应用广泛,端到端的视觉-语言-动作(VLA)模型能简化整体系统架构。
- 现有问题:
- 现有方法多依赖 离散文本 CoT,对视觉信息过度抽象 → 导致 时空关系模糊、细粒度信息丢失、模态切换不自然。
- 现有视觉生成方法存在 缺乏语义信息、训练成本高 的不足。
- 研究动机:
受人类驾驶认知启发,作者提出 更直观的时空 CoT 方法,避免信息损失,构建端到端视觉推理管道;同时设计了新的 预训练范式与生成方法,缓解现有生成模型的问题。
自动驾驶应基于现实世界?还是纯文本符号逻辑?
Is autonomous driving better modeled on real-world simulation and imagination than on pure symbolic logic?
作者提出时空思维链(spatio-temporal CoT)充当中间推理步骤,使视觉语言模型(VLM)能够作为基于当前观测和未来预测进行轨迹规划的逆动力学模型,而不是直接输出思考文本。这消除了跨模态转换(例如,将视觉感知转换为文本描述以进行推理)所导致的语义差距,建立了端到端的视觉推理管道,使模型能够直接进行视觉因果推断。
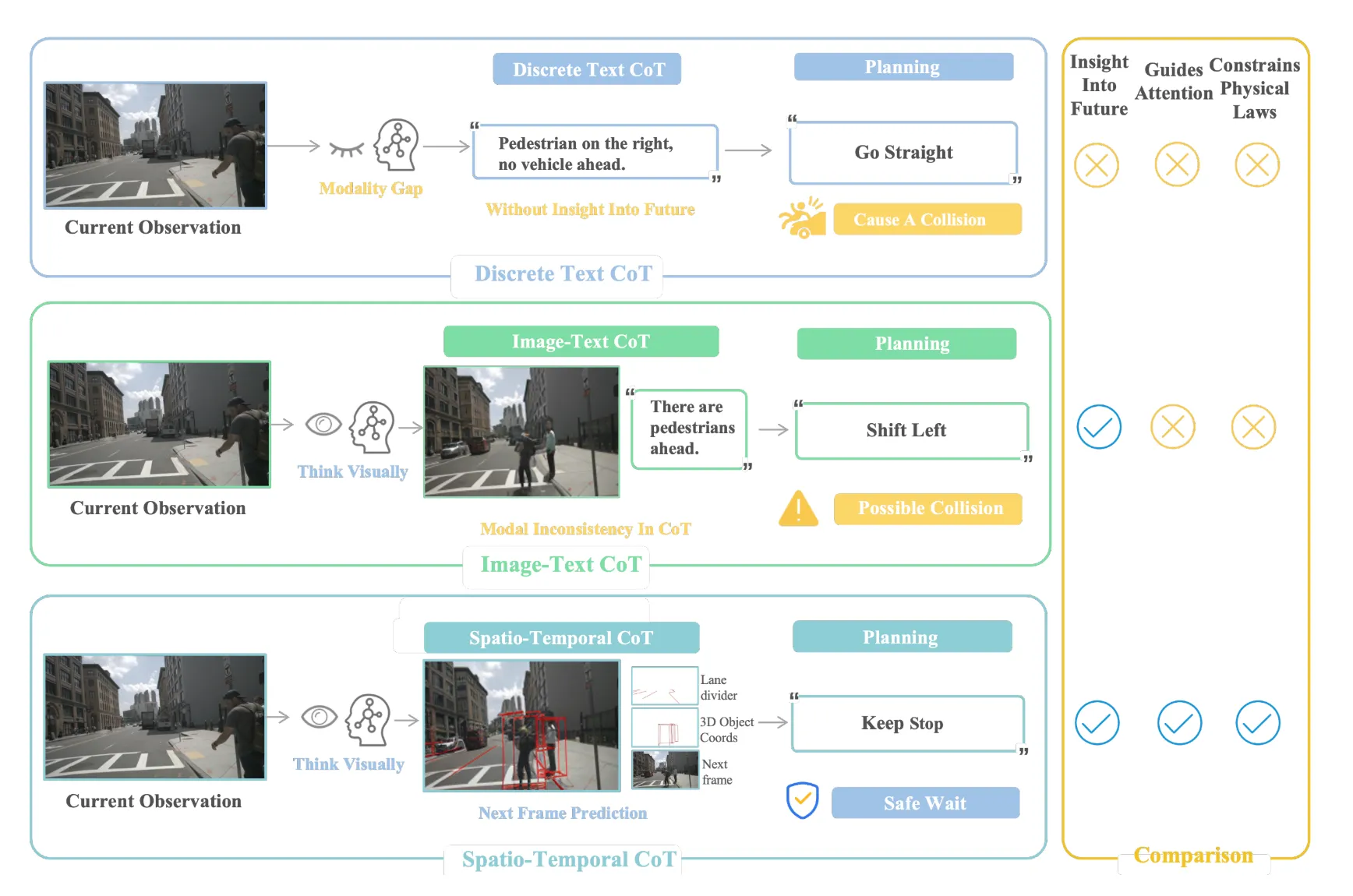
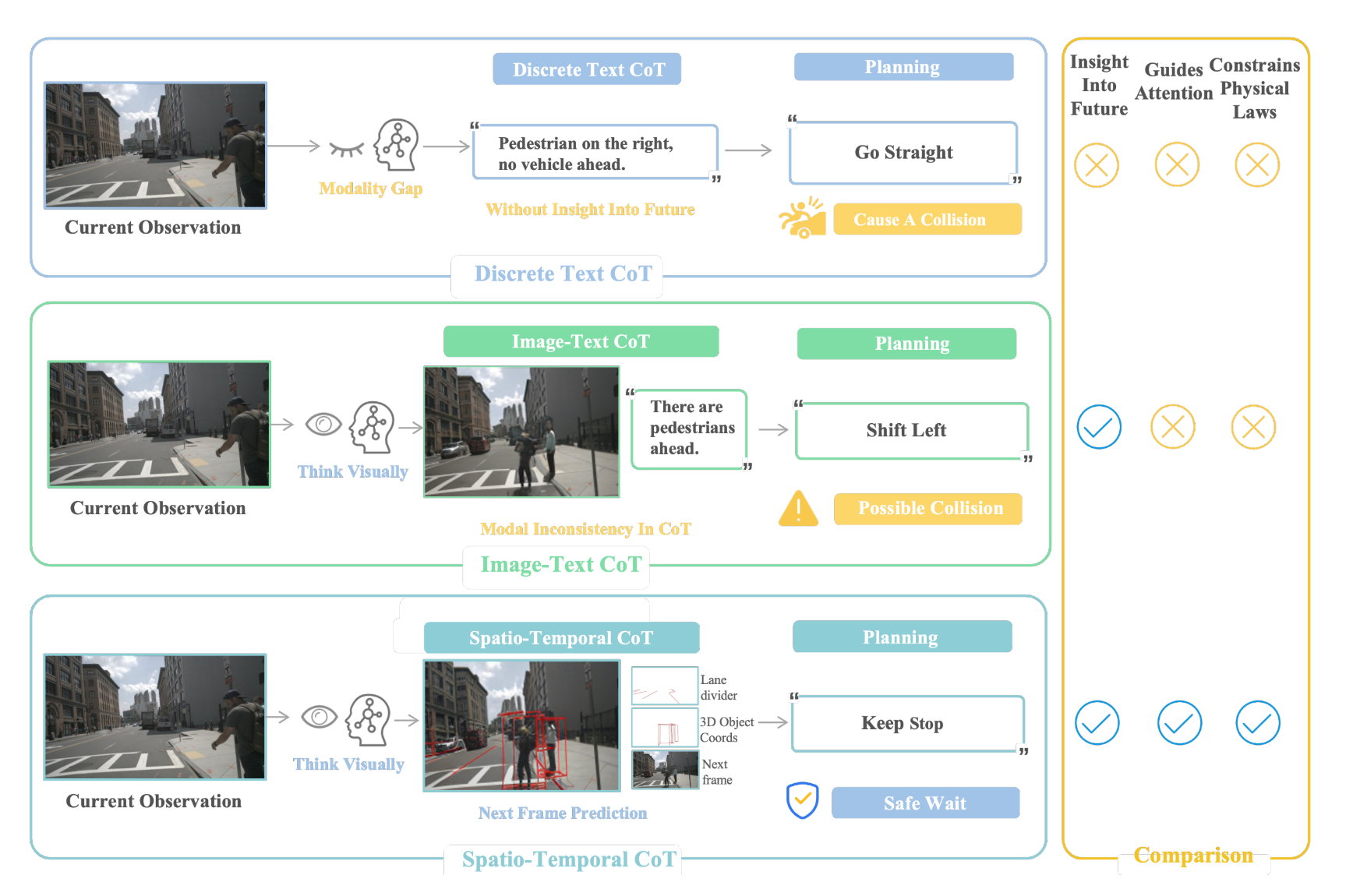
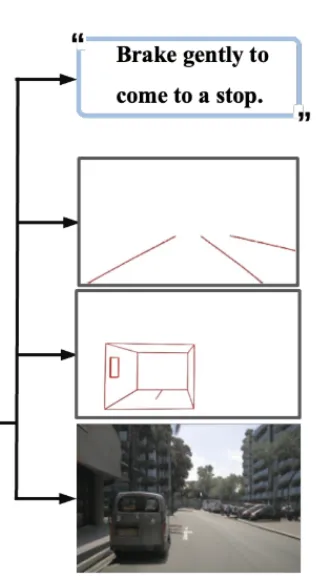
如上图所示,对不同思维链(CoT)的比较。文本型思维链表达提供的信息不足。图文型思维链的模态之间不一致。所提出的时空思维链能够捕捉未来的时间和空间关系。
最上方的图显示文本思维链不具备洞察未来、引导注意力和遵循物理定律的能力。
中间的图就是利用视觉思考能力,图像-文本 思维链来进行决策,具备了洞察未来的能力,但是并不能做出很好的决策和遵循物理定律的能力。
最下方是作者提出的 时空思维链 ,利用视觉思考出道路线路、3D物体坐标并预测下一帧,能够做好正确的决策,具备洞察未来、良好决策和遵循物理定律三种特征。
实现方法
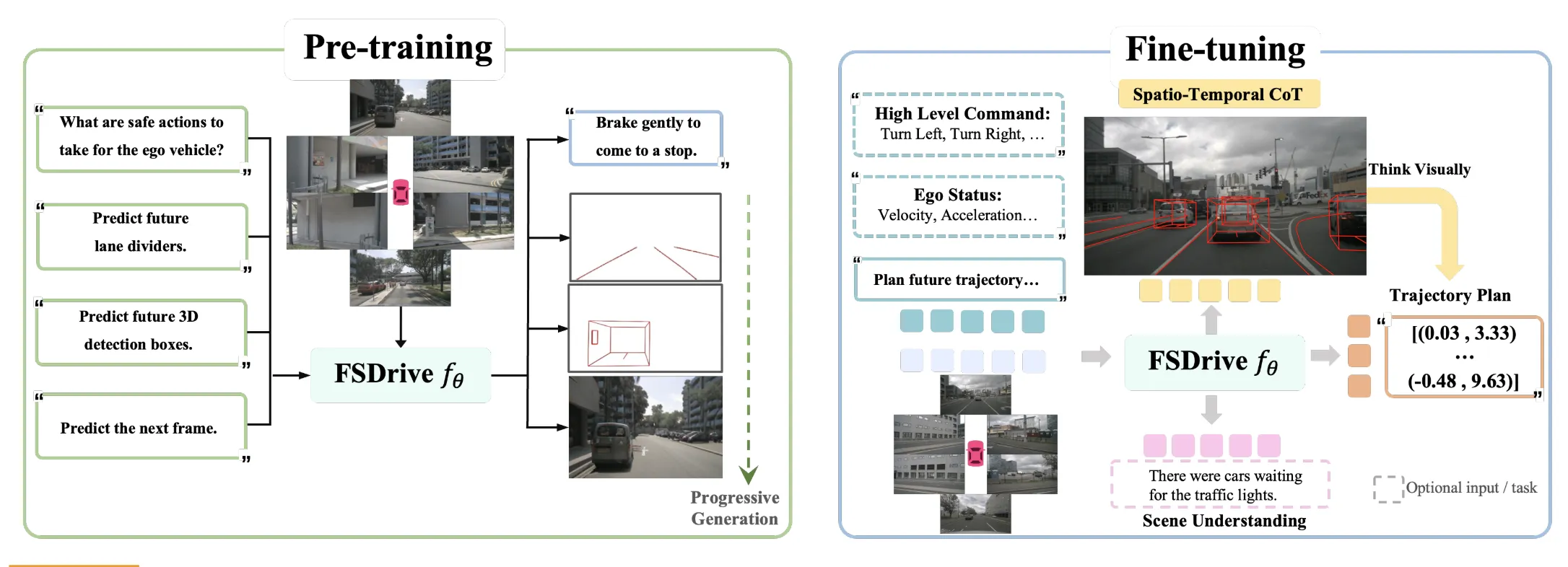
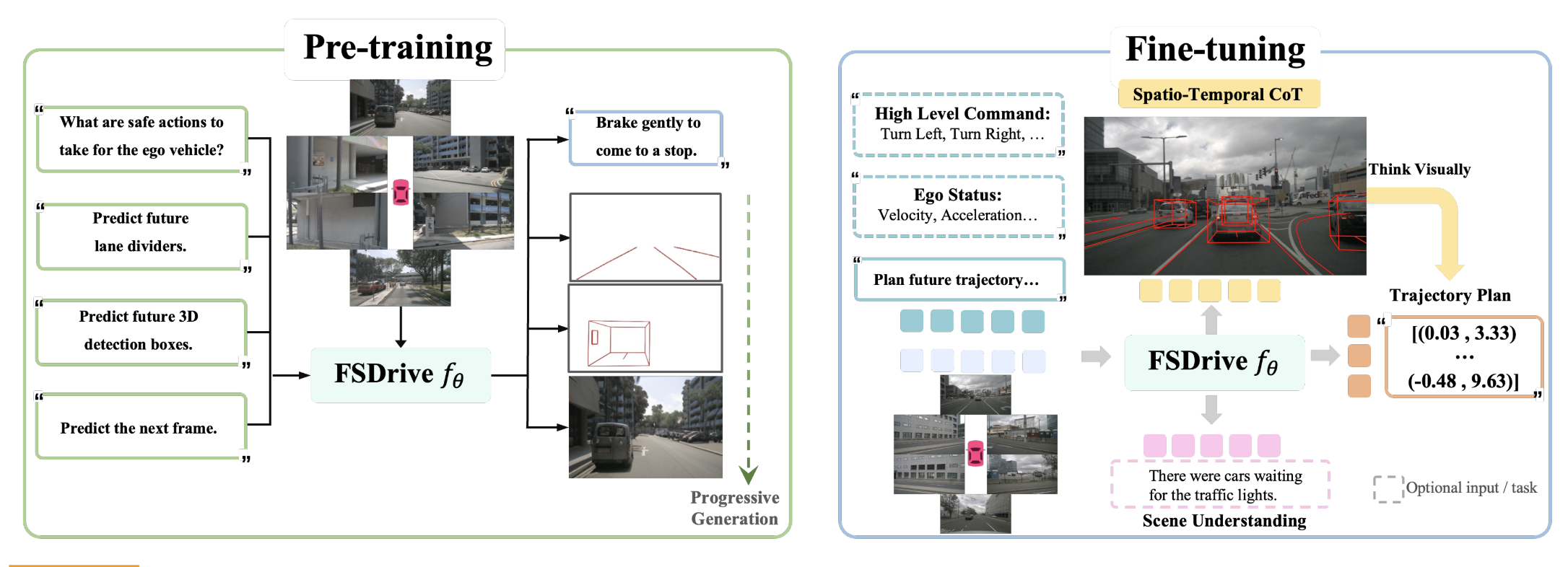
为了实现统一的预训练,多模态大型语言模型(MLLMs)需要视觉生成能力。在提取视觉信息时,通常采用矢量量化变分自编码器(VQ-VAE)将图像编码为离散标记。然而,这些标记缺乏语义信息,从而损害了下游理解性能。
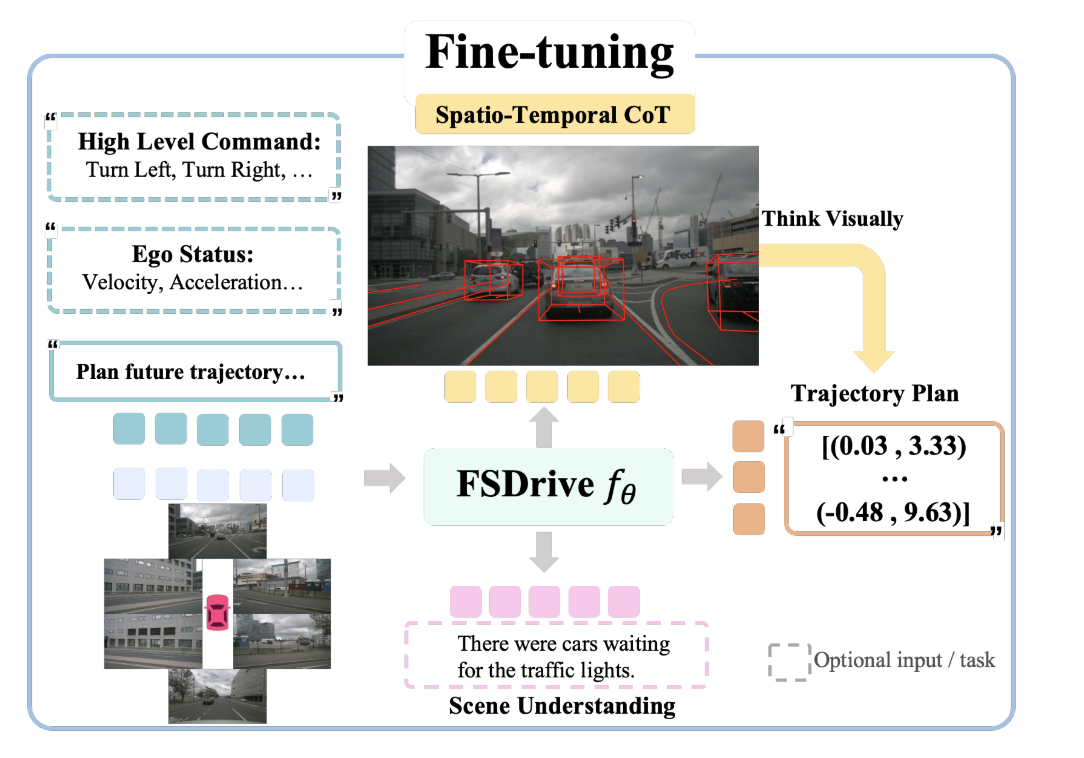
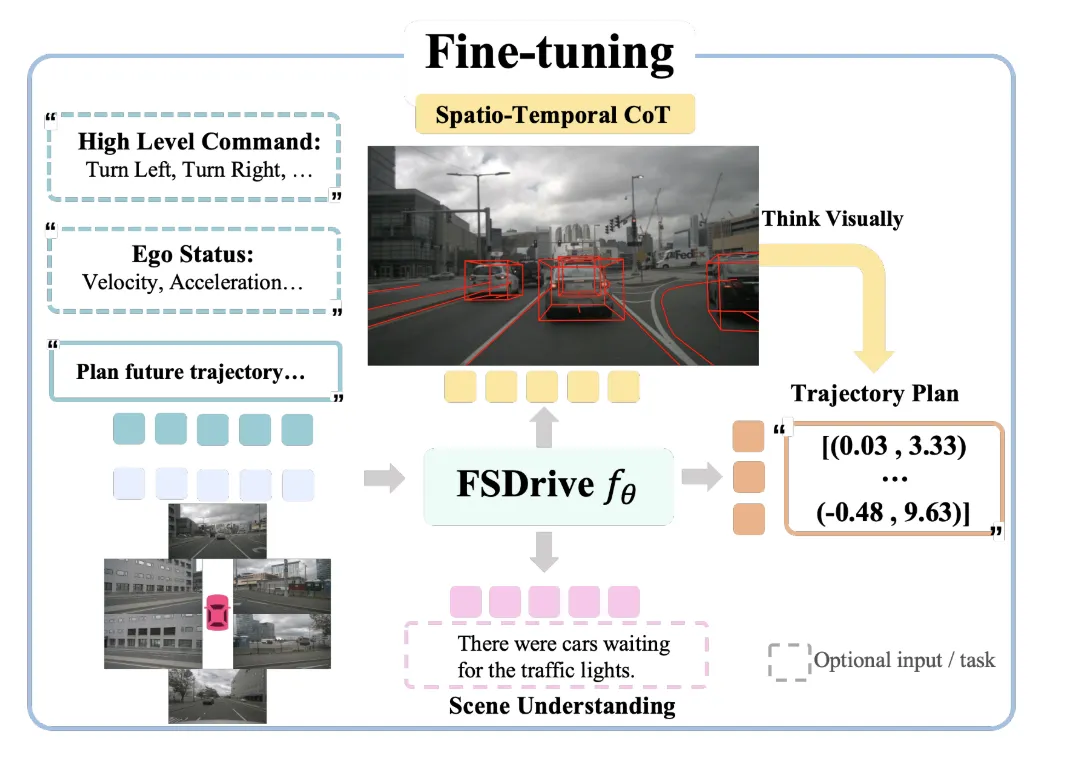
以当前周围图像和任务指令为输入,以预测下一个标记的形式训练多模态大语言模型(MLLM)。MLLM预测未来的时空思维链(CoT),然后根据当前观测和预测的未来生成轨迹。作者的方法直接构建在任何现有的采用基于视觉Transformer(ViT)编码器将图像转换为连续特征的MLLM之上。作者保留原始的MLLM架构,不改变任何结构组件,以保持与预训练权重的兼容性。
上述图中,左侧的Pre-training部分用于视觉理解的预训练。为了在预训练阶段有效保留原生MLLM的语义理解能力,采用VQA任务。分别个一个图片四个问题,通过视觉问答任务保留多模态大型语言模型的理解能力,并激活其视觉生成能力以预测未来帧
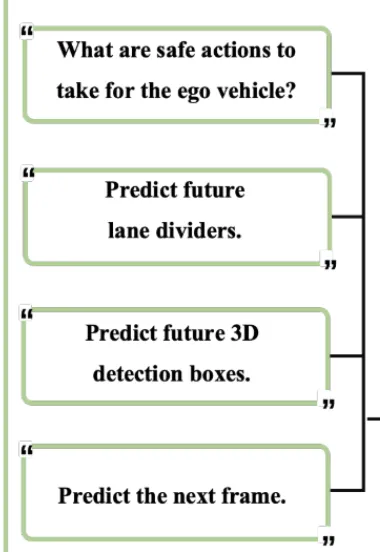
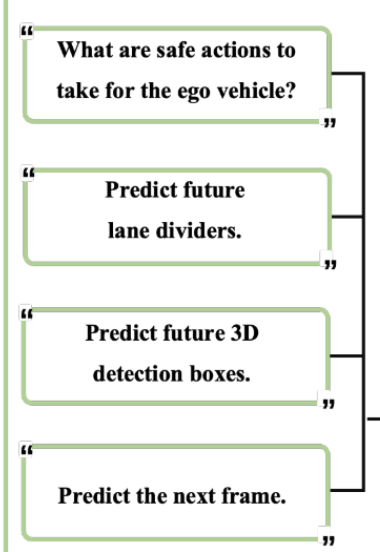
分别经过MLLM进行处理后得到:决策、道路线条、3d物体坐标、预测的下一帧
最开始用分离的几个VQA生成对应结果,后来就无需单一生成,而是直接整合所有结果到同一个帧内部。时空思维链(CoT)将整体未来场景、明确的车道分隔线和三维检测结果整合到单个未来帧中,作为中间推理步骤。使用单个模型同时训练这些任务,通过不同的任务提示在推理过程中实现特定任务的预测。
实验结果
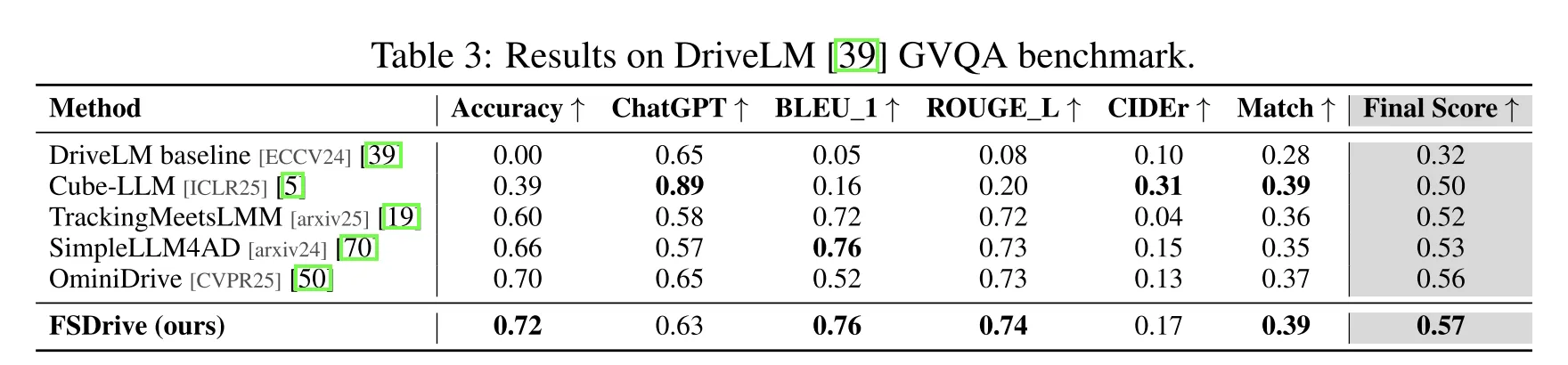

结论
本文提出了FSDrive,一种基于时空思维链(CoT)的自动驾驶框架,它能让视觉语言模型(VLMs)进行视觉思考。通过中间图像形式的推理步骤将未来场景生成与感知结果统一起来,我们的FSDrive消除了跨模态转换导致的语义鸿沟,并建立了端到端的视觉推理 pipeline。
视觉语言模型扮演双重角色:作为世界模型,预测带有车道分隔线和三维检测的未来图像帧
作为逆动力学模型,基于当前观测和未来预测来规划轨迹。为了实现视觉语言模型中的视觉生成,提出了一种统一视觉生成与理解的预训练范式,以及一种渐进式的由易到难视觉思维链,以增强自回归图像生成。大量实验结果证明了所提FSDrive方法的有效性,推动自动驾驶向视觉推理方向发展。
推荐阅读: