Whole-Body Conditioned Egocentric Video Prediction(NeurIPS2025)
主页链接:https://dannytran123.github.io/PEVA/
文献速读
背景与动机
人类运动具有高维度、复杂时间依赖和强结构性,是视觉感知与长期规划的重要信号。对具身智能体而言,能够基于全身运动进行学习与预测,对于实现自然交互和智能决策至关重要。然而,这一方向面临三大挑战:
- 动作表示复杂 —— 需要捕捉高维、结构化且动态变化的运动特征;
- 动作与视觉耦合非线性 —— 身体运动与视觉结果之间关系高度依赖上下文,建模难度大;
- 数据学习困难 —— 人类运动具有个体差异与高可变性,视觉后果又往往细微且难以捕捉。
因此,亟需一种能够有效建模人类全身动作及其视觉后果的框架,以提升预测质量、语义一致性和对细粒度动作的控制能力,为具身智能体的长期规划与自主学习奠定基础。
📷 什么是 Egocentric Vision?
特点
- 📷 视角独特:画面内容围绕拍摄者(自己)的身体、手部、眼前物体展开;
- 🤲 交互性强:常常包含与环境的互动,比如抓取物品、走动、运动等;
- ⏱ 时序依赖:因为视频跟随佩戴者移动,动作和视觉场景在时间上紧密耦合;
- 🧠 语义关联:更关注“我正在看什么/做什么”,而不是单纯的外部场景。
应用场景
- 🕶️ AR/VR:提升沉浸式体验;
- 🤖 具身智能体(机器人):学习人类如何观察和操作世界;
- 🏋️ 行为识别/运动分析:识别人类活动和意图;
- 🍳 日常任务理解:比如“我在做饭时手上拿的是什么”。
对比Exocentric Vision(第三人称)
| 对比维度 | 第一人称 (Egocentric) | 第三人称 (Exocentric) |
|---|---|---|
| 视角来源 | 相机随身佩戴(眼镜、头盔、胸前) | 相机固定在外部(房间角落、三脚架等) |
| 画面内容 | 以观察者的身体、手部和眼前物体为主 | 以观察者为场景中的“对象” |
| 交互信息 | 包含人与物体的交互(如抓取、操作) | 多为场景全局视角,交互细节较少 |
| 空间感 | 强调“我能看到什么” | 强调“别人能看到我在做什么” |
| 时序特征 | 动作和视觉强耦合,连续性强 | 更关注完整动作的外部表现 |
| 应用方向 | AR/VR、机器人学习、意图识别、日常任务理解 | 运动分析、行为识别、监控、影视拍摄 |
| 难点 | 视角抖动大、遮挡多、场景变化快 | 容易丢失交互细节,缺乏沉浸感 |
PEVA与先前的模型不同之处
创新点
- 虽然先前的研究将姿态视为目标,但PEVA的模型将其用作第一视角视频预测的输入,从而逆转了典型的运动生成设置。
- PEVA模型将每个动作定义为一个高维向量,该向量同时对整体身体动态和详细的关节运动进行编码。
- 设计了一种结构化动作表示,该表示既保留了整体身体动态,又保留了局部关节运动,使用了一种分层编码来捕捉人体运动的运动学树结构。
- 开发了一种基于条件扩散Transformer的新型架构,该架构能够有效建模身体运动与视觉结果之间复杂的非线性关系。
- 利用了一个大规模的同步第一视角视频和动作捕捉数据集,该数据集提供了学习这些复杂关系所需的训练信号。
额外技术栈
- powerful diffusion-based generators Moiton Diffusion Model(3D动作生成模型)
- the kinematic tree 运动学树建模
为什么采用Random Timeskips的策略?
人类活动通常跨越较长的时间范围,其动作可能需要数秒才能完成。同时,视频作为一种原始信号,需要大量计算资源进行处理。为了更高效地处理视频,我们在训练过程中引入了随机时间跳跃,并将时间跳跃作为一种动作来告知模型的预测。


这使得模型能够同时学习短期运动动态和长期活动模式。学习长期动态对于建模诸如伸手、弯腰或行走等活动尤为重要,这些活动的完整动作需要数秒才能展开。在实践中,我们从32秒的窗口中采样16帧视频帧。
如何评估动作模型效果?
首先,为了评估该模型是否能忠实模拟基于动作的未来观测结果,我们使用LPIPS(Zhang等,2018)和DreamSim(Fu等,2023),这两种指标用于衡量与真实值的感知相似度和语义相似度。
其次,为了评估生成样本的整体质量和真实感,我们报告了FID。
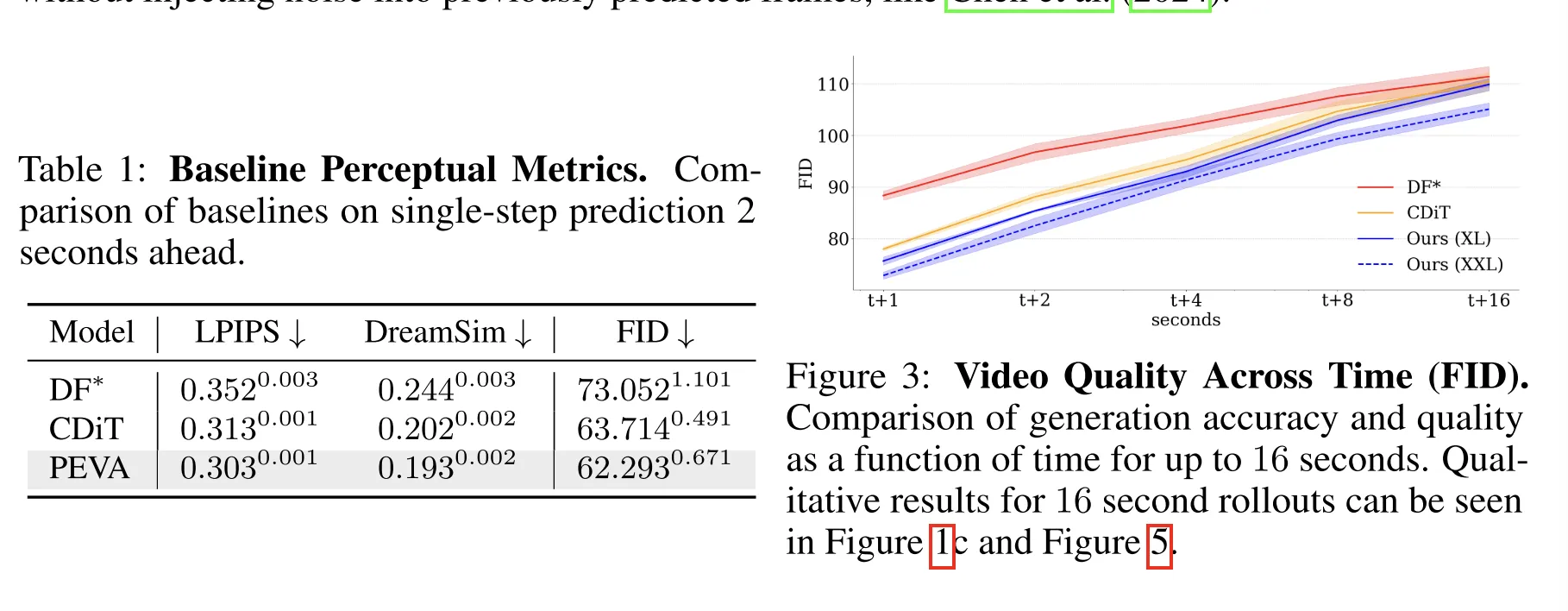
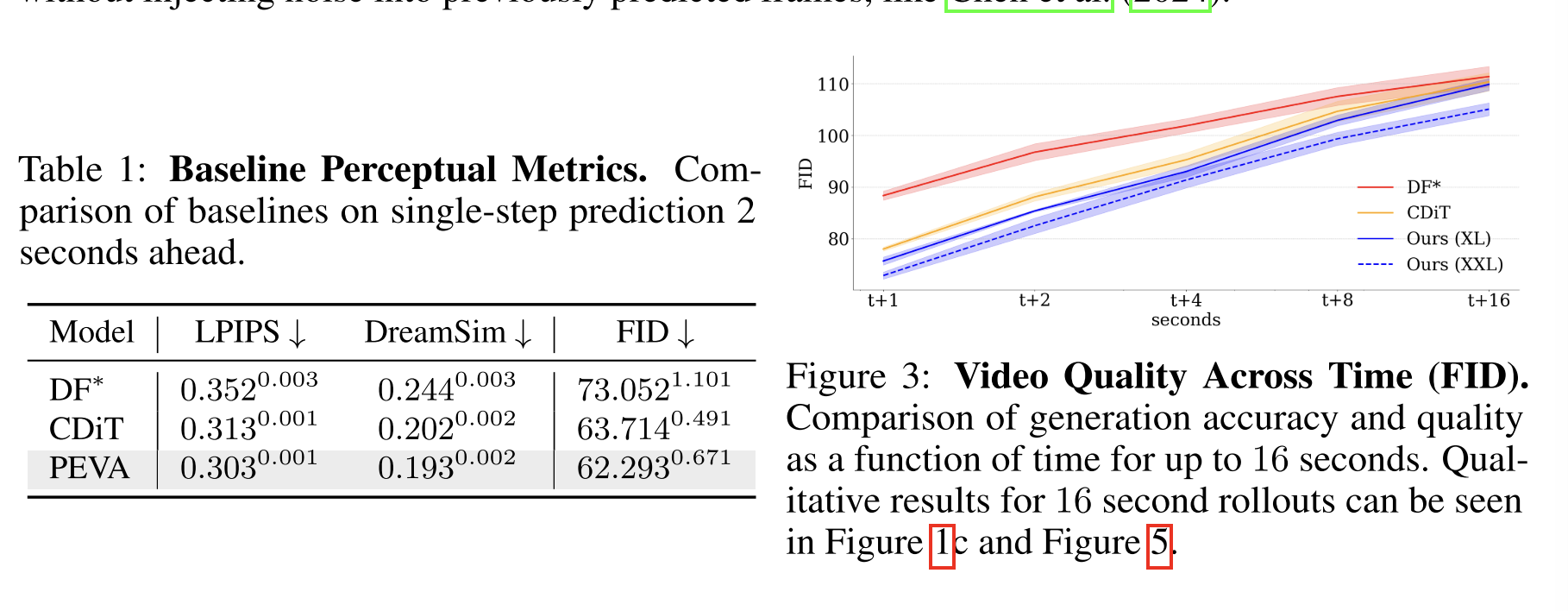
结论、局限性与未来方向
结论
通过测量与目标图像的LPIPS相似度来对每个动作候选的最终预测进行排序。作者发现,PEVA通过模拟动作候选,能够有效地支持规划。
局限
尽管PEVA模型在基于全身运动预测第一视角视频方面展现出了良好的结果,但仍存在一些局限性,这些局限性为未来的工作指明了方向。首先,我们的规划评估尚处于初步阶段——我们仅在模拟环境中对左臂或右臂的候选动作进行选择。
虽然这初步表明该模型能够预测身体运动带来的视觉后果,但它尚不支持长时程规划或完整的轨迹优化。将PEVA扩展到闭环控制或交互式环境中是下一步的关键工作。
其次,该模型目前缺乏对任务意图或语义目标的显式条件控制。我们的评估使用图像相似度作为代理目标。未来的工作可以探索将PEVA与高级目标条件控制相结合,或者整合以对象为中心的表征。
推荐阅读: