DocKS-RAG: Optimizing Document-Level Relation Extraction through LLM-Enhanced Hybrid Prompt Tuning(ICML2025)
原文链接:https://arxiv.org/abs/2504.09823
论文速读
| 一、基本信息 | 标题 | DocKS-RAG: Optimizing Document-Level Relation Extraction through LLM-Enhanced Hybrid Prompt Tuning |
|---|---|---|
| 作者 | Xiaolong Xu, Yibo Zhou, Haolong Xiang, Xiaoyong Li, Xuyun Zhang, Lianyong Qi, Wanchun Dou | |
| 关键词 | Document-level Relation Extraction, Large Language Models, Knowledge Graph, Retrieval-Augmented Generation, Prompt Tuning | |
| 二、文章概述 | 本文针对文档级关系抽取(RE)中现有方法难以融合实体-关系结构知识及跨句语义推理的问题,提出DocKS-RAG框架。该框架通过构建文档级知识图谱(DocKG)捕获实体-关系结构交互,设计句子级语义检索增强生成(SetRAG)机制丰富上下文语义,并结合混合提示调优(Hybrid Prompt Tuning)提升大语言模型(LLMs)的任务适应性。实验表明,DocKS-RAG在DocRED和Re-DocRED数据集上的Ign-F1和F1分数均优于现有方法。 | |
| 三、研究背景 | 文档级关系抽取需从长文档中提取实体间跨句、跨段落的隐含关系,现有方法存在局限:基于预训练语言模型(PLMs)的方法难以建模实体-关系结构知识,导致复杂关系提取性能不佳;图基方法虽关注结构信息,但缺乏充足上下文语义,且存在图与文本语义错位问题;最新大语言模型(LLMs)方法依赖语义理解,但仍忽略图知识与语言模型的异质性。因此,需融合结构知识与语义信息以提升LLMs在文档级RE任务的性能。 | |
| 四、研究思路 | 提出研究问题 | 如何融合结构知识与语义信息,解决LLMs在文档级RE中结构建模不足及语义错位问题。 |
| 构建研究框架 | 设计DocKS-RAG框架,包含DocKG(结构知识)、SetRAG(语义信息)及混合提示调优模块。 | |
| 选择研究方法 | 采用图神经网络(GNNs)构建DocKG,BGE模型进行句子嵌入与检索,LORA实现参数高效微调(PEFT)。 | |
| 分析数据 | 在DocRED和Re-DocRED数据集上,通过对比实验、消融实验及参数敏感性分析验证框架有效性。 | |
| 得出结论 | DocKS-RAG通过结构与语义融合显著提升LLMs的文档级RE性能,各组件(DocKG、SetRAG、混合提示)均为关键贡献。 | |
| 五、研究结果 | DocKS-RAG在DocRED和Re-DocRED数据集上的Ign-F1和F1分数均优于PLMs、图基及LLMs基线方法,验证框架整体有效性。 | |
| 文档级知识图谱(DocKG)检索阈值τeq=0.7时性能最优,过高或过低会引入噪声或限制全局理解。 | ||
| 句子级检索(SetRAG)取Top5相关句子时性能最佳,过多无关句子会降低模型可靠性。 | ||
| 消融实验显示,移除DocKG、SetRAG或混合提示调优后,模型性能显著下降,证明各组件必要性。 | ||
| 六、研究结论、不足与展望 | 研究结论 | DocKS-RAG通过融合文档级知识图谱的结构知识与句子级语义检索的上下文信息,结合混合提示调优,有效提升了LLMs在文档级关系抽取任务的性能,在基准数据集上实现了Ign-F1和F1分数的全面超越。 |
| 研究的创新性 | 1. 提出DocKG与SetRAG融合机制,解决结构知识与语义信息的互补问题;2. 设计混合提示生成方法,将图检索子图与句子检索结果转化为自然语言提示,缓解语义错位;3. 采用PEFT(LORA)实现LLMs高效微调,平衡性能与计算成本。 | |
| 研究的不足之处 | DocKG构建依赖预定义关系集,对开放域关系适应性有限;SetRAG检索阈值与TopK句子数量需人工调参,影响模型鲁棒性;框架复杂度较高,实际部署时需优化并行处理效率。 | |
| 研究展望 | 1. 扩展至开放域关系抽取,探索动态关系类型学习;2. 引入自动阈值调整机制,提升SetRAG和DocKG检索的自适应能力;3. 优化框架效率,适配更大规模LLMs及多模态文档;4. 应用于特定领域(如生物医药、法律)知识图谱构建,验证跨领域适用性。 | |
| 研究意义 | 本文为文档级关系抽取提供了融合结构知识与语义信息的新范式,推动LLMs在复杂知识提取任务中的应用;提出的混合提示调优方法可迁移至其他知识密集型NLP任务(如问答、摘要),具有广泛学术与应用价值。 |
背景与动机
背景
- 文档级关系抽取(RE)需要从长文档中识别跨句、跨段落的实体关系。
现有方法存在不足:
- 基于PLMs的方法:难以显式建模实体-关系结构知识,复杂关系提取性能差。
- 图基方法:虽然关注结构,但缺乏充分的上下文语义,且图与文本语义容易错位。
- LLMs方法:擅长语义理解,但忽略图结构知识,与语言模型存在异质性。
动机
- 当前方法在结构建模和语义融合上均存在缺陷,导致文档级关系抽取效果受限。
- 为了提升LLMs在文档级RE任务中的表现,需要一种方法能够 同时融合结构知识与语义信息,解决结构建模不足和语义错位的问题。
现有多数文本实体抽取方法是如何实现?
Most of existing works conduct transfer learning on pre- trained language models (PLMs), which allows for richer contextual representation to improve the performance
大多数现有研究在预训练语言模型(PLMs)上进行迁移学习,这能够获得更丰富的上下文表示以提升性能。
然而,这类基于预训练语言模型的方法在整合实体间交互等结构知识方面存在不足。此外,当前研究难以推断不同句子中实体之间的隐含关系,从而导致预测效果不佳。
传统的预训练语言模型(PLMs),如BERT,已被广泛应用于关系抽取(RE)中。
什么是DocKS-RAG?
DocKS-RAG引入了额外的结构知识和语义信息,以进一步提升文档级关系抽取的性能。
具体而言,DocKS-RAG可以从文档数据中构建文档级知识图谱,以更好地捕捉实体和关系之间的结构信息。
然后,设计了一种句子级语义检索增强生成机制,通过检索相关的上下文语义信息来考虑不同句子间的相似性。此外,作者还提出了一种针对特定文档级关系抽取任务的大语言模型(LLMs)混合提示微调方法。
SetRAG
A Sentence-level Semantic Retrieval-Augmented Generation (SetRAG) mechanism is designed to consider the similarity of different sentences by retrieving the relevant contextual semantic information.
SetRAG是一个一种句子级语义检索增强生成机制,通过检索相关的上下文语义信息来考虑不同句子的相似性。它通过以下步骤增强文档级关系抽取的语义理解:
- 句子分割与知识库构建:将文档分割为独立句子,使用预训练语言模型将句子转换为语义向量,构建句子级知识库(SetKB)。
- 语义检索:针对用户查询,通过余弦相似度从SetKB中检索TopK相关句子,捕捉跨句语义关联。
- 提示生成:将检索到的句子及其包含的实体关系三元组转换为自然语言提示(PSetRAG),与文档级知识图谱生成的结构化提示融合,形成混合提示输入LLM。
该机制通过引入上下文语义相似性,有效缓解了传统方法难以处理的跨句隐式关系推理问题,实验表明在Re-DocRED数据集上,当检索Top5句子时模型F1分数达到峰值75.31。
LLM抽取文档实体关系
LLM-based实体抽取方法通常通过以下流程实现:
- 上下文理解:利用LLM对长文本的语义理解能力,识别实体边界和类型(如BIO标注或零样本分类)
- 提示工程:设计特定prompt(如"从文本中提取人名、组织名")引导模型生成结构化实体
- 少样本/零样本学习:通过少量标注样例或关系描述,使模型适应特定领域实体类型
- 后处理优化:结合规则或外部知识库修正模型输出的实体边界错误
主要存在以下问题:
- 实体边界模糊性:对嵌套实体(如"中国科学院大学"包含"中国科学院")和指代消解处理能力不足
- 领域适配性差:通用LLM在专业领域(如医学、法律)的实体识别准确率显著下降
- 输出格式不稳定:生成式抽取可能产生非结构化结果,需额外处理格式一致性
- 计算成本高:长文档处理需多次调用API或大模型推理,时效性难以保障
- 幻觉现象:模型可能生成文本中不存在的"伪实体",尤其在低资源场景下
需要强调的是,此分析基于领域共识而非原文数据。与本文提出的DocKS-RAG框架关注的关系抽取不同,实体抽取更聚焦于实体本身的识别与分类,二者在上下文建模和知识融合层面存在方法学共通性。
总体而言,以往基于预训练语言模型(PLM)的方法致力于有效融合实体与关系之间的交互以实现更好的抽取。目前,近期提出的基于大型语言模型(LLM)的研究仍未能缓解结构知识与语义信息之间不对齐问题。
DocKS-RAG框架的实现步骤
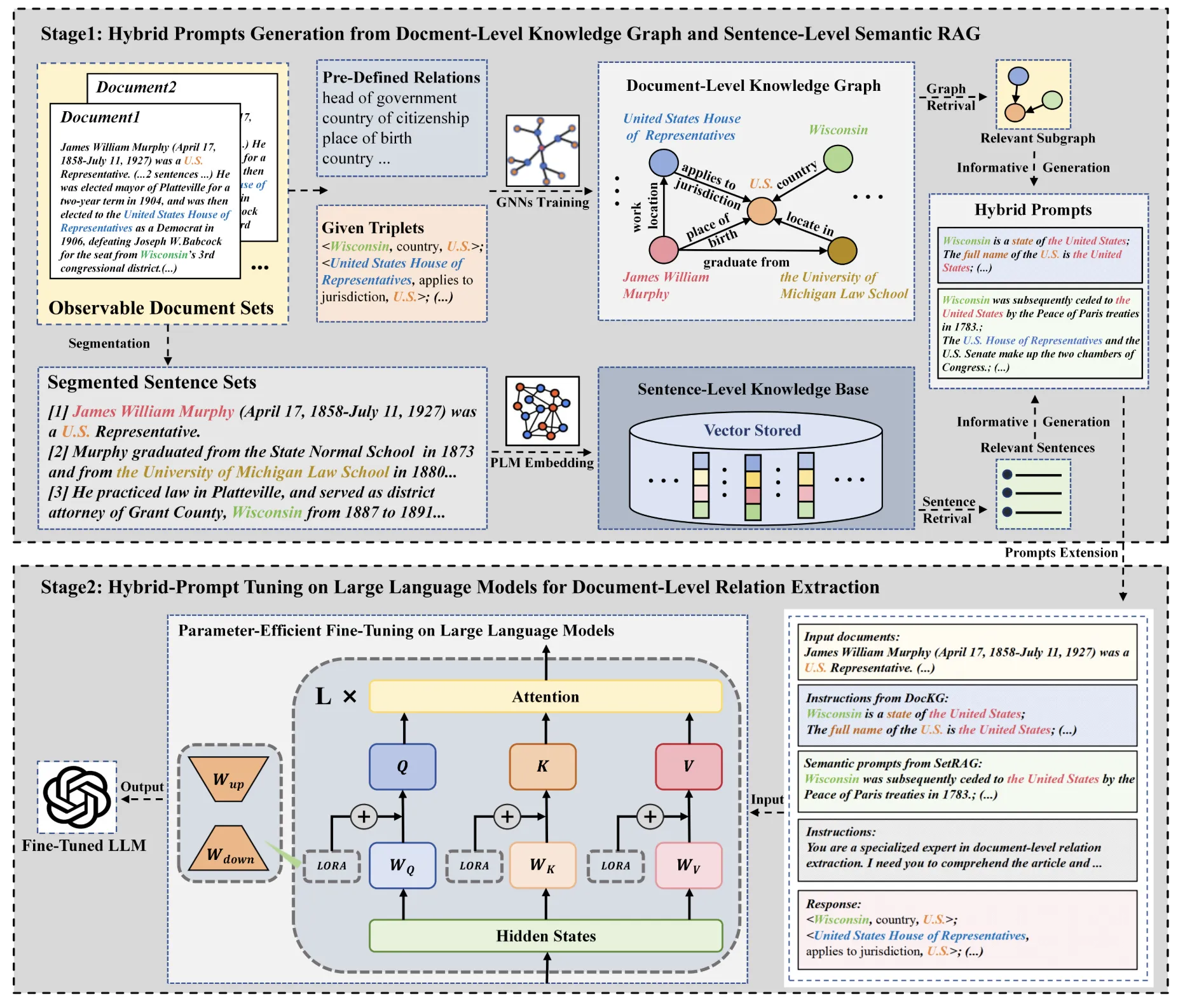
- 混合提示词生成(Hybrid Prompts Generation)
对于查询q,我们生成混合提示词 $P_{\text{Hybrid}}$,其融合了来自DocKG的相关结构化信息和SetRAG的相关语义信息。混合提示词的构建表示为:
$$
P{\text{Hybrid}} = \text{Concat}(P{\text{DocKG}}(q), P_{\text{SetRAG}}(q))
$$
其中:
- $P_{\text{DocKG}}(q)$ 表示从DocKG中检索到的相关结构化知识
- $P_{\text{SetRAG}}(q)$ 表示从SetRAG中检索到的Topk相关语义信息。
也就是说,混合提示词是通过分别从DocKG中进行检索匹配,外加在SetRAG中进行匹配的两个结果,然后进行融合最终生成混合的提示词。最后提示词再给到LLM
- 大语言模型的参数高效微调(Parameter-Efficient Fine-Tuning on LLMs)
作者提出的 DocKS-RAG框架中采用了 LORA这种通用的适配器训练方法来微调 LLM。具体而言,通过集成适配器模块,无需修改预训练 LLM 的整个参数集即可实现微调。此外,适配器模块 A 在更小的文档级 RE任务特定数据集上进行训练,这使得框架能够快速适应并最大程度降低计算复杂度。使用 PEFT 的输出计算如下:
$$
O{PEFT}=LLM(P{Hybrid};θ+A)
$$
其中θ是预训练LLM的原始参数,A是指与将被微调的适配器模块相关的可学习参数。
事实上就是将混合提示词输入到LLM中,然后加上LORA微调即可。
总结:DocKS-RAG框架主要包括两个阶段:
在阶段1中:通过结合相关检索到的文档级结构知识和丰富的语义信息来生成内容丰富的混合提示,这些知识和信息基于构建的文档级知识图谱和句子级知识库。
在阶段2中:使用扩展的混合提示对大型语言模型(LLMs)进行参数高效微调,以进一步增强大型语言模型在复杂文档级关系抽取(RE)任务上的适应性和性能。
结论
- 与以往基于预训练语言模型(PLMs)的方法相比,在额外构建的文档级知识图谱(DocKG)上进行图检索,以更好地捕捉文档中的结构知识。这减轻了结构化图知识与语言模型之间的异质性。
- 通过结合DocKG和SetRAG检索相关信息并生成混合提示词(Hybird-Prompt)方法,并与LORA微调集成,进一步增强了大型语言模型的适应性,以实现更好的提取效果。
- 在所有数据集上,DocKS-RAG在Ign-F1和F1分数指标上均优于竞争方法,这表明DocKS-RAG的框架在文档级关系抽取任务上的有效性。
补充知识
LLM与结构化知识图谱的heterogeneity(异质性)主要体现在数据表示与学习范式的本质差异。
- 数据形式差异:LLM以连续文本为输入,通过预训练学习上下文语义关联;知识图谱(KG)则以离散三元组(实体-关系-实体)存储结构化事实,强调实体间显式拓扑关系。
- 知识类型差异:LLM擅长捕捉隐式语义(如句子间语义相似性),但难以直接建模实体交互的结构规则;KG则显式编码实体关系的结构化知识,但缺乏文本的上下文语义细节。
- 推理方式差异:LLM依赖统计模式进行语义推理,而KG推理基于图结构的路径遍历和逻辑规则(如传递性、对称性)。
实验图表
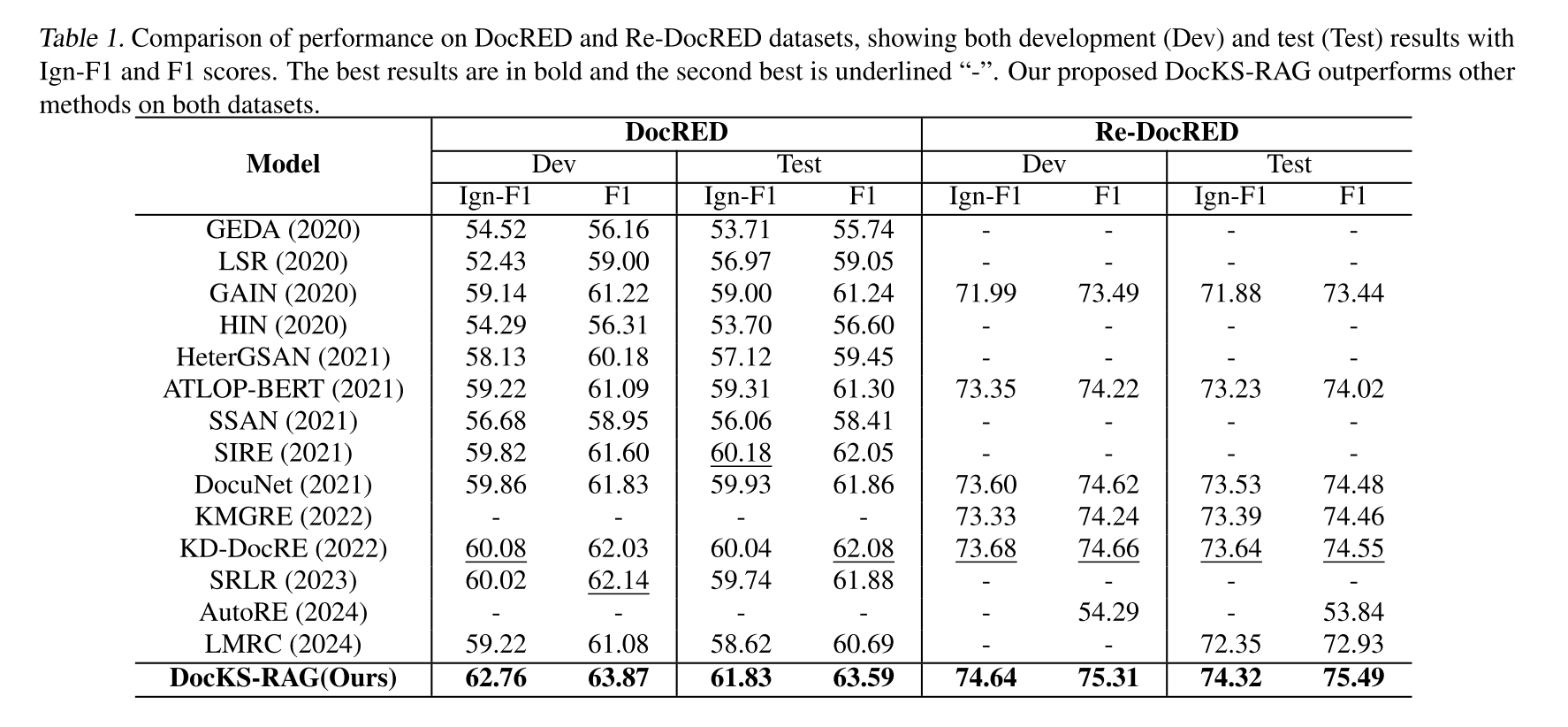
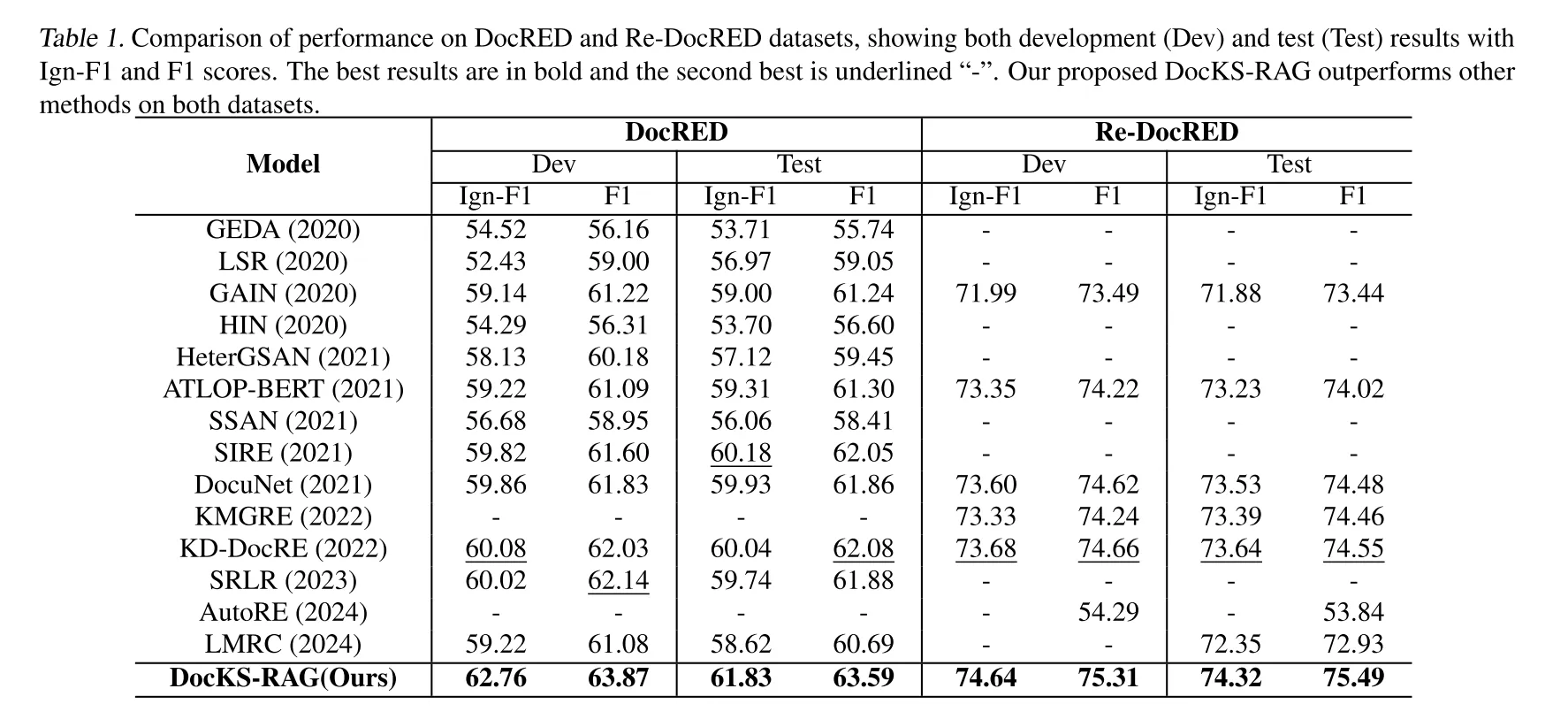
表1. DocRED和Re-DocRED数据集上的性能比较,展示了开发集(Dev)和测试集(Test)的Ign-F1和F1分数。最佳结果用粗体表示,第二佳结果用下划线“-”表示。我们提出的DocKS-RAG在两个数据集上均优于其他方法。
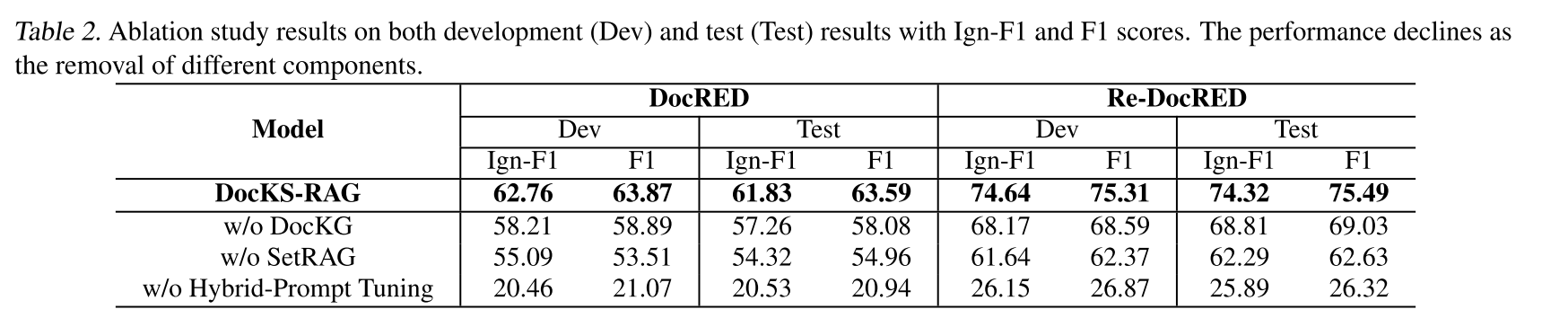
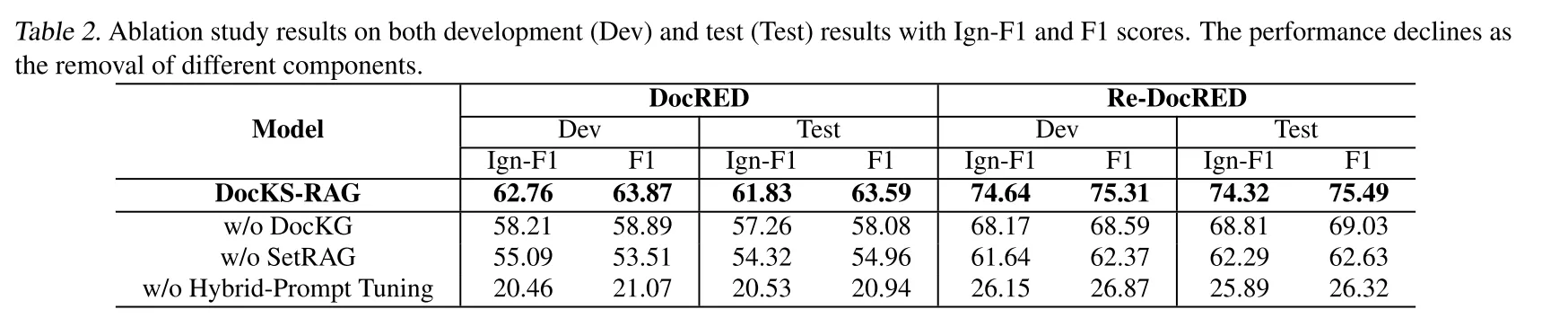
表2.开发集(Dev)和测试集(Test)上消融实验结果,包括Ign-F1和F1分数。随着不同组件的移除,性能有所下降。
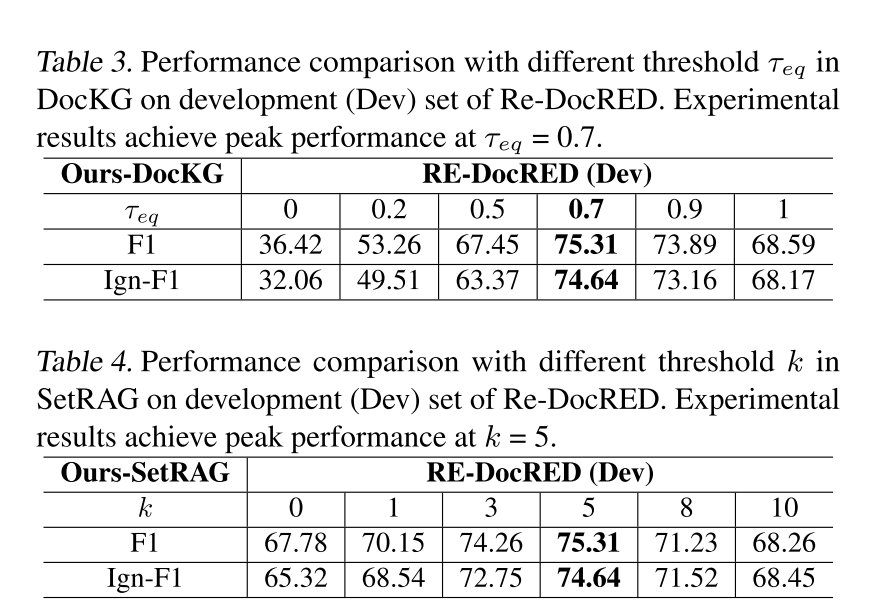
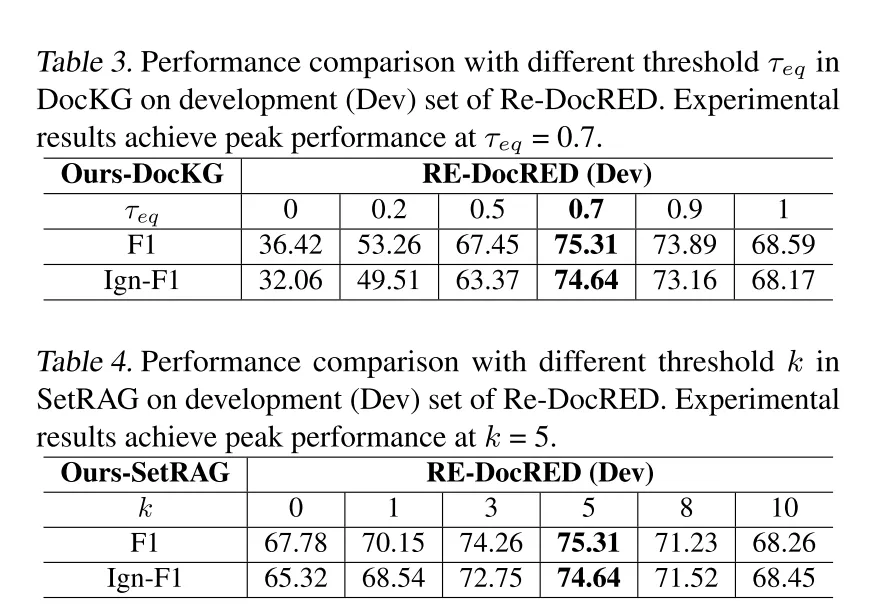
表3. 在Re-DocRED的开发集(Dev)上使用DocKG时不同阈值τeq的性能比较。实验结果在τeq =0.7时达到最佳性能。
表4. 在Re-DocRED的开发集(Dev)上使用SetRAG时不同阈值k的性能比较。实验结果在k=5时达到峰值性能。
展望
结论总结
作者提出了一个新颖且高效的DocKS-RAG框架,用于增强大型语言模型(LLMs)在复杂文档级关系抽取(RE)任务中的适应性和性能。在两个基准数据集上的大量实验表明,作者提出的DocKS-RAG显著优于最先进的方法。
存在问题
未来,作者将继续探索如何将DocKS-RAG应用于不同领域,以及如何增强DocKS-RAG在不同规模大型语言模型上的可扩展性等问题。
可能的拓展应用
需要强调的是,此分析基于领域共识而非原文数据,具体方向需结合实际应用场景的需求与资源约束进一步验证。
- 跨领域适配
- 垂直领域迁移:将框架应用于生物医药、法律文书、金融报告等专业领域,需构建领域特定文档知识图谱(如医疗实体关系图谱)和语义检索库,优化实体识别与关系类型定义以适配领域特性。
- 多语言支持:扩展至多语言文档场景,需解决跨语言实体对齐和语义检索的语言差异问题,可结合多语言预训练模型(如XLM-RoBERTa)优化知识图谱构建。
- LLM规模适配与效率优化
- 轻量化部署:针对不同规模LLM(如7B/13B/70B参数模型)设计自适应混合提示调优策略,在资源受限场景下通过知识蒸馏或模型压缩保留核心性能。
- 动态知识更新:研究DocKG的增量更新机制,支持实时文档流处理(如新闻、社交媒体),避免全量重构图谱的高成本。
- 任务扩展与融合
- 多模态文档处理:结合图像、表格等非文本信息,构建多模态知识图谱,增强跨模态实体关系推理能力(如论文图表中的实体关联)。
- 与问答系统集成:利用SetRAG机制检索相关语义信息,提升基于文档的复杂问答性能,支持多跳推理型问题(如“文档中A实体通过哪些中间实体与B相关?”)。
- 实际应用场景落地
- 知识图谱自动构建:应用于企业知识库、学术数据库,自动化抽取实体关系并更新图谱,减少人工标注成本。
- 信息安全与合规审计:从合同、政策文档中提取敏感实体关系(如“数据传输方-接收方”),辅助合规性检查。
关键挑战与应对思路
- 领域知识适配:需设计领域自适应的阈值参数(如DocKG构建中的τer、检索阈值τeq),并引入领域本体知识指导关系推理。
- 计算效率平衡:通过并行化DocKG构建与SetRAG检索,或采用近似检索算法(如FAISS)降低实时处理延迟。
推荐阅读: